4.1. ドメイン層の実装¶
目次
4.1.1. ドメイン層の役割¶
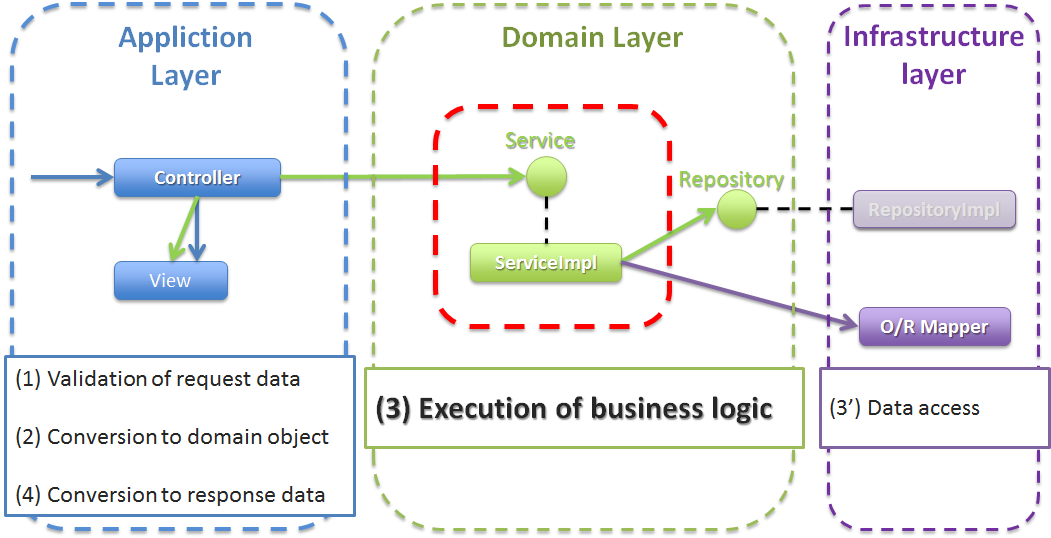
ドメイン層は、 アプリケーション層に提供する業務ロジックを実装するためのレイヤとなる。
ドメイン層の実装は、以下3つに分かれる。
項番 分類 説明
本ガイドラインでは、以下2点を目的として、EntityクラスおよびRepositoryを作成する構成を推奨している。
- 業務ロジック(Service)と業務データへアクセスするためのロジックを分離することで、業務ロジックの実装範囲をビジネスルールに関する実装に専念させる。
- 業務データに対する操作をRepositoryに集約することで、業務データへのアクセスの共通化を行う。
Note
本ガイドラインでは、EntityクラスおよびRepositoryを作成する構成を推奨しているが、この構成で開発することを強制するものではない。
作成するアプリケーションの特性、プロジェクトの特性(開発体制や開発プロセスなど)を加味して、採用する構成を決めて頂きたい。
4.1.2. ドメイン層の開発の流れ¶
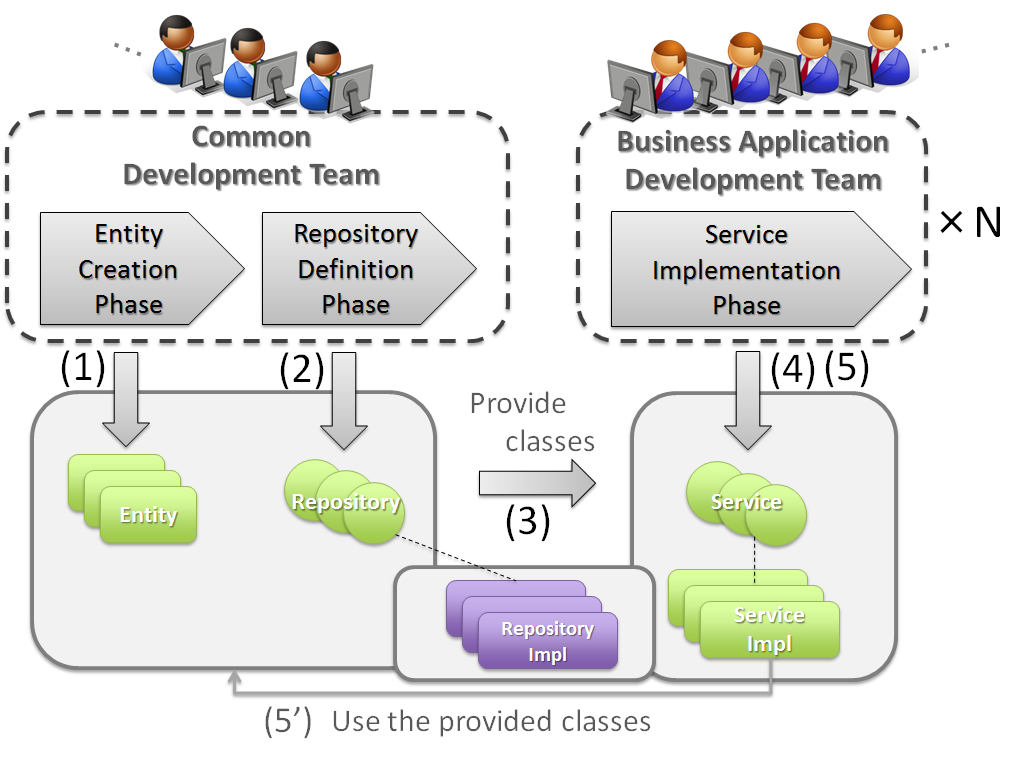
項番 担当チーム 説明 Warning
開発規模が大きいシステムでは、アプリケーションを複数のチームに分担して開発を行う場合がある。 その場合は、EntityクラスおよびRepositoryを設計するための共通チームを設けることを強く推奨する。
共通チームを設ける体制が組めない場合は、EntityクラスおよびRepositoryの作成せずに、 ServiceからO/R Mapper(Mybatisなど)を直接呼び出して、業務データにアクセスする方法を採用することを検討すること。
4.1.3. Entityの実装¶
4.1.3.1. Entityクラスの作成方針¶
項番 方針 補足 java.util.List<E>またはjava.util.Set<E>のどちらかを使用する。FK先のテーブルに対応するEntityのことを、本ガイドライン上では、関連Entityと呼ぶ。java.lang.Stringなどの基本型で扱う。
Warning
テーブルが正規化されていない場合は、 以下の点を考慮して EntityクラスおよびRepositoryを作成する方式を採用すべきか検討した方がよい。 特に正規化されていないテーブルとJPAとの相性はあまりよくないので、テーブルが正規化されていない場合は、JPAを使用してEntityオブジェクトを操作する方式は採用しない方が無難である。
EntityクラスとRepositoryを作成する方式を採用することを推奨するが、作成するアプリケーションの特性、 プロジェクトの特性(開発体制や開発プロセスなど)を加味して、採用する構成を決めて頂きたい。
Note
テーブルは正規化されていないが、アプリケーションとして、正規化されたEntityとして業務データを扱いたい場合は、 インフラストラクチャ層のRepositoryImplの実装として、Mybatisを採用することを推奨する。
Mybatisは、データベースで管理されているレコードとオブジェクトをマッピングするという考え方ではなく、 SQLとオブジェクトをマッピングという考え方で開発されたO/R Mapperであるため、 SQLの実装次第で、テーブル構成に依存しないオブジェクトへのマッピングができる。
4.1.3.2. Entityクラスの作成例¶
4.1.3.2.1. テーブル構成¶
商品を購入する際に必要となる業務データを保持するテーブルは、以下の構成となっている。
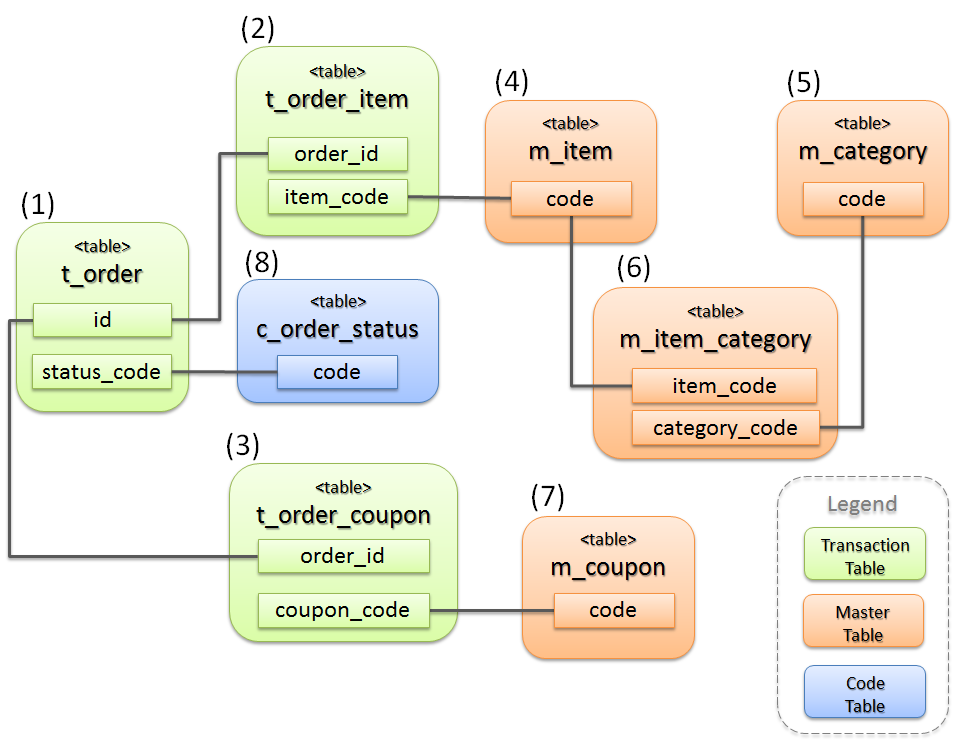
項番 分類 テーブル名 説明
4.1.3.2.2. Entity構成¶
上記テーブルから作成方針に則ってEntityクラスを作成すると、以下のような構成となる。

項番 クラス名 説明 OrderItemおよびOrderCouponを複数保持する。Itemを保持する。Couponを保持する。Categoryを複数保持する。ItemとCategoryの紐づけは、m_item_categoryテーブルによって行われる。
上記のエンティティ図をみると、ショッピングサイトのアプリケーションとして主体のEntityクラスとして扱われるのは、 Orderクラスのみと思ってしまうかもしれないが、主体となる得るEntityクラスはOrderクラス以外にも存在する。
以下に、主体のEntityとしてなり得るEntityと、主体のEntityにならないEntityを分類する。
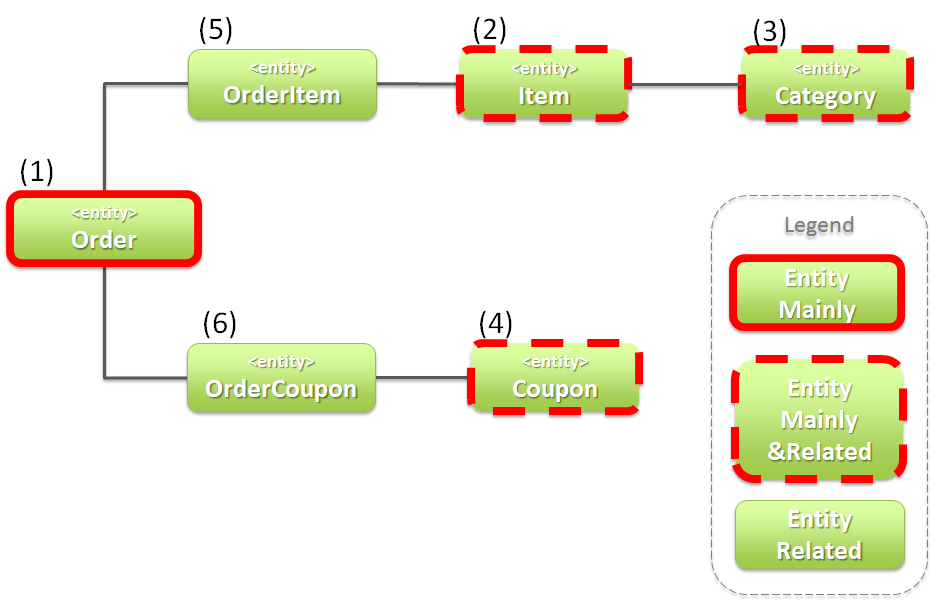
ショッピングサイトのアプリケーションを作成する上で、主体のEntityとしてなり得るのは、以下4つである。
項番 Entityクラス 主体のEntityとなる得る理由
ショッピングサイトのアプリケーションを作成する上で、主体のEntityとならないのは、以下2つである。
項番 Entityクラス 主体のEntityにならない理由
4.1.4. Repositoryの実装¶
4.1.4.1. Repositoryの役割¶
Repositoryは、以下2つの役割を担う。
- Serviceに対して、Entityのライフサイクルを制御するための操作(Repositoryインタフェース)を提供する。Entityのライフサイクルを制御するための操作は、EntityオブジェクトへのCRUD操作となる。
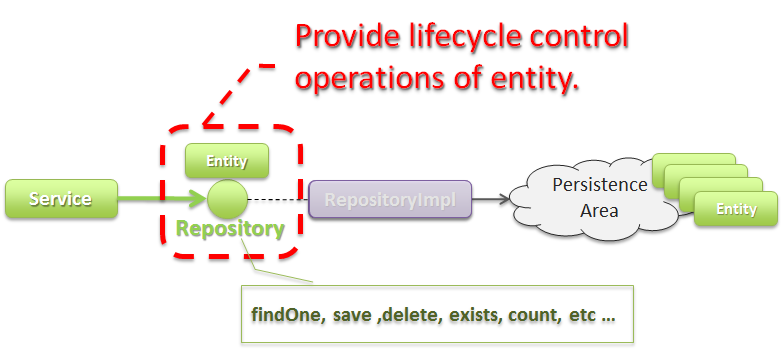
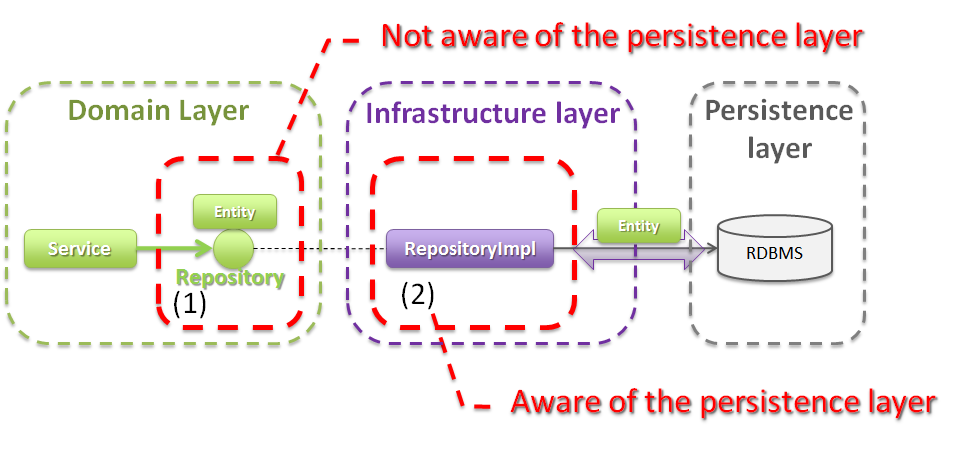
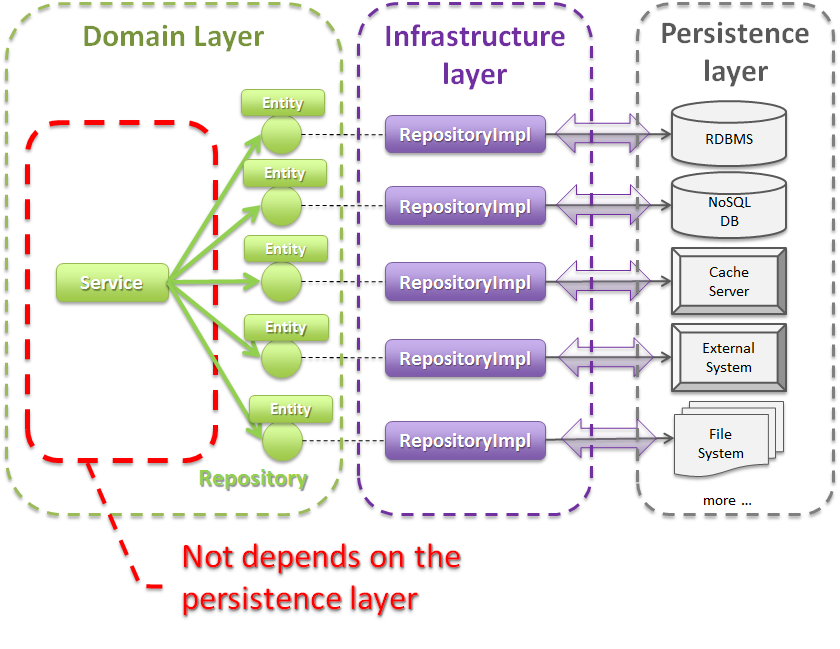
- Entityを永続化する処理(Repositoryインタフェースの実装クラス)を提供する。Entityオブジェクトは、アプリケーションのライフサイクル(サーバの起動や、停止など)に依存しないレイヤに、永続化しておく必要がある。Entityの永続先は、リレーショナルデータベースになることが多いが、NoSQLデータベース、キャッシュサーバ、外部システム、ファイル(共有ディスク)などになることもある。実際の永続化処理は、O/R Mapperなどから提供されているAPIを使って行う。この役割は、インフラストラクチャ層のRepositoryImplで実装することになる。詳細については、インフラストラクチャ層の実装を参照されたい。
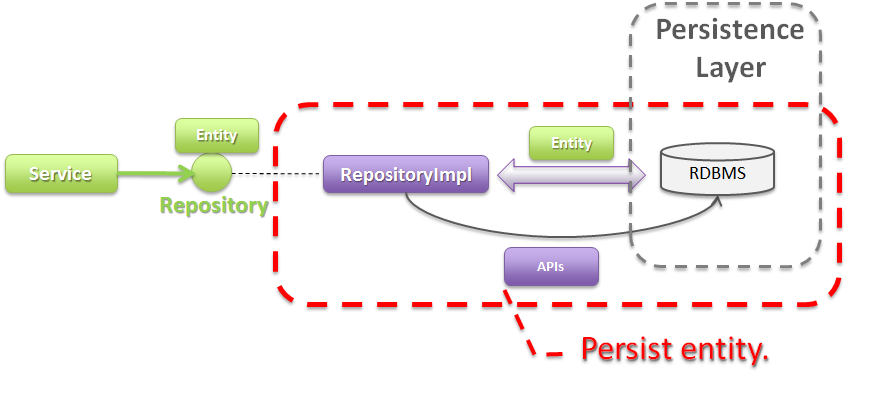
4.1.4.2. Repositoryの構成¶
Repositoryは、RepositoryインタフェースとRepositoryImplで構成され、それぞれ以下の役割を担う。
項番 クラス(インタフェース) 役割 説明
Note
永続先に依存したロジックを、Serviceから100%排除できるのか?
永続先の制約や、使用するライブラリの制約などにより、排除できないケースもある。 可能な限り、永続先に依存するロジックは、Serviceではなく、RepositoryImplで実装することを推奨するが、 永続先に依存するロジックを排除するのが難しい場合や、排除することで得られるメリットが少ない場合は、 無理に排除せず、業務ロジック(Service)の処理として、永続先に依存するロジックを実装してもよい。
排除できない具体例として、Spring Data JPAから提供されている
org.springframework.data.jpa.repository.JpaRepositoryインタフェース のsaveメソッドの呼び出し時に、一意制約エラーをハンドリングしたい場合である。 JPAではEntityへの操作はキャッシュされ、トランザクションコミット時にSQLを発行する仕組みになっている。 そのため、JpaRepositoryのsaveメソッドを呼び出しても、SQLは発行されないので、一意制約違反をロジックでハンドリングすることができない。 JPAでは、明示的にSQLを発行する手段として、キャッシュされている操作を反映するためのメソッド(flushメソッド)があり、 JpaRepositoryではsaveAndFlush、flushというメソッドが同じ目的で提供されている。 そのため、Spring Data JPAのJpaRepositoryを使って、一意制約違反エラーをハンドリングする必要がある場合は、 JPA依存のメソッド(saveAndFlushや、flush)を呼び出す必要がある。Warning
Repositoryを設ける最も重要な目的は、永続先に依存するロジックを、業務ロジックから排除することではないという点である。 最も重要な目的は、業務データへアクセスするための操作をRepositoryへ分離することで、業務ロジック(Service)の実装範囲をビジネスルールに関する実装に専念させるという点である。 結果として、永続先に依存するロジックは業務ロジック(Service)ではなく、Repository側に実装される事になる。
4.1.4.3. Repositoryの作成方針¶
Repositoryは原則以下の方針で作成する。
項番 方針 補足
4.1.4.4. Repositoryの作成例¶
4.1.4.4.1. Repository構成¶
Entityクラスの作成例の説明で使用した、EntityクラスのRepositoryを作成すると、以下のような構成となる。
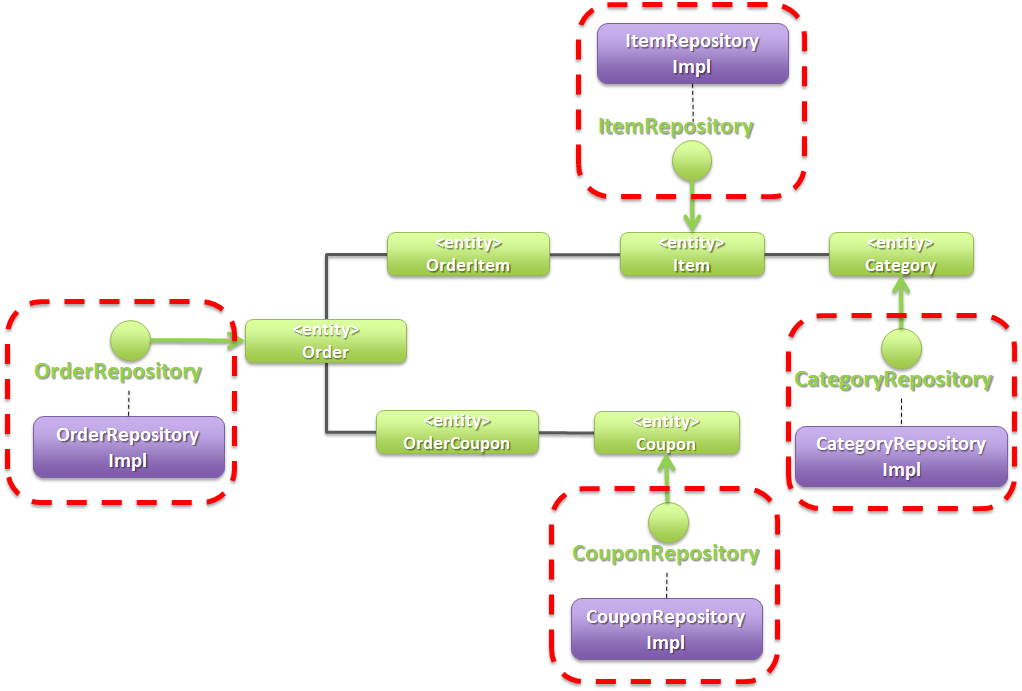
4.1.4.5. Repositoryインタフェースの定義¶
4.1.4.5.1. Repositoryインタフェースの作成¶
以下にRepositoryインタフェースの作成例を紹介する。
SimpleCrudRepository.java
このインタフェースは、シンプルなCRUD操作のみを提供している。メソッドのシグネチャは、Spring Dataから提供されているCrudRepositoryインタフェースや、PagingAndSortingRepositoryインタフェースを参考に作成している。public interface SimpleCrudRepository<T, ID extends Serializable> { // (1) T findOne(ID id); // (2) boolean exists(ID id); // (3) List<T> findAll(); // (4) Page<T> findAll(Pageable pageable); // (5) long count(); // (6) T save(T entity); // (7) void delete(T entity); }
項番 説明 java.util.Iterableであったが、サンプルとしては、java.util.Listにしている。PageableインタフェースおよびPageインタフェースはSpring Dataより提供されているクラス(インターフェース)である。
TodoRepository.java
下記は、チュートリアルで作成したTodoエンティティのRepositoryを、上で作成した
SimpleCrudRepositoryインタフェースベースに作成した場合の例である。// (1) public interface TodoRepository extends SimpleCrudRepository<Todo, String> { // (2) long countByFinished(boolean finished); }
項番 説明 SimpleCrudRepositoryインタフェースから提供されていないメソッドを追加している。ここでは、「指定したタスクの終了状態に一致するTodoエンティティの件数を取得するメソッド」を追加している。
4.1.4.5.2. Repositoryインタフェースのメソッド定義¶
CrudRepositoryや、PagingAndSortingRepositoryと同じシグネチャにすることを推奨する。java.lang.Iterableではなく、ロジックで扱いやすいインタフェース(java.util.Collectionや、java.util.List)でもよい。
項番 メソッドの種類 ルール
1件検索系のメソッド
- メソッド名は、条件に一致するEntityを、1件取得するためのメソッドであることを明示するために、findOneByで始める。
- メソッド名のfindOneBy以降は、検索条件となるフィールドの物理名、または、論理的な条件名などを指定し、どのような状態のEntityが取得されるのか、推測できる名前とする。
- 引数は、条件となるフィールド毎に用意する。ただし、条件が多い場合は、条件をまとめたDTOを用意してもよい。
- 返り値は、Entityクラスを指定する。
複数件検索系のメソッド
- メソッド名は、条件に一致するEntityを、すべて取得するためのメソッドであることを明示するために、 findAllBy で始める。
- メソッド名のfindAllBy以降は、検索条件となるフィールドの物理名または論理的な条件名を指定し、どのような状態のEntityが取得されるのか推測できる名前とする。
- 引数は、条件となるフィールド毎に用意する。ただし、条件が多い場合は、条件をまとめたDTOを用意してもよい。
- 返り値は、Entityクラスのコレクションを指定する。
複数件ページ検索系のメソッド
- メソッド名は、条件に一致するEntityの該当ページ部分を取得するためのメソッドである事を明示するために、 findPageBy で始める。
- メソッド名のfindPageBy以降は、検索条件となるフィールドの物理名または論理的な条件名を指定し、どのような状態のEntityが取得されるのか推測できる名前とする。
- 引数は、条件となるフィールド毎に用意する。ただし、条件が多い場合は、条件をまとめたDTOを用意してもよい。ページネーション情報(取得開始位置、取得件数、ソート情報)は、Spring Dataより提供されている
Pageableインタフェースとすることを推奨する。- 返り値は、Spring Dataより提供されている
Pageインタフェースとすることを推奨する。
件数のカウント系のメソッド
- メソッド名は、条件に一致するEntityの件数をカウントするためのメソッドである事を明示するために、 countBy で始める。
- 返り値は、long型にする。
- メソッド名のcountBy以降は、検索条件となるフィールドの物理名または論理的な条件名を指定し、どのような状態のEntityの件数が取得されるのか推測できる名前とする。
- 引数は、条件となるフィールド毎に用意する。ただし、条件が多い場合は、条件をまとめたDTOを用意してもよい。
存在判定系のメソッド
- メソッド名は、条件に一致するEntityが存在するかチェックするためのメソッドである事を明示するために、 existsBy で始める。
- メソッド名のexistsBy以降は、検索条件となるフィールドの物理名または論理的な条件名を指定し、どのような状態のEntityの存在チェックを行うのか推測できる名前とする。
- 引数は、条件となるフィールド毎に用意する。ただし、条件が多い場合は、条件をまとめたDTOを用意してもよい。
- 返り値は、boolean型にする。
Note
更新系のメソッドも、同様のルールに則り、追加することを推奨する。 findの部分が、updateまたはdeleteとなる。
Todo.java(Entity)
public class Todo implements Serializable { private String todoId; private String todoTitle; private boolean finished; private Date createdAt; // ... }
TodoRepository.java
public interface TodoRepository extends SimpleCrudRepository<Todo, String> { // (1) Todo findOneByTodoTitle(String todoTitle); // (2) List<Todo> findAllByUnfinished(); // (3) Page<Todo> findPageByUnfinished(); // (4) long countByExpired(int validDays); // (5) boolean existsByCreateAt(Date date); }
項番 説明
4.1.4.5.3. RepositoryImplの作成¶
RepositoryImplの実装については、インフラストラクチャ層の実装を参照されたい。
4.1.5. Serviceの実装¶
4.1.5.1. Serviceの役割¶
Serviceは、以下2つの役割を担う。
- Controllerに対して業務ロジックを提供する。業務ロジックは、アプリケーションで使用する業務データの参照、更新、整合性チェックおよびビジネスルールに関わる各種処理で構成される。業務データの参照および更新処理をRepository(またはO/R Mapper)に委譲し、Serviceではビジネスルールに関わる処理の実装に専念することを推奨する。
Note
ControllerとServiceで実装するロジックの責任分界点について
本ガイドラインでは、ControllerとServiceで実装するロジックは、以下のルールに則って実装することを推奨する。
- クライアントからリクエストされたデータに対する単項目チェック、相関項目チェックはController側(Bean ValidationまたはSpring Validator)で行う。
- Serviceに渡すデータへの変換処理(Bean変換、型変換、形式変換など)は、ServiceではなくController側で行う。
- ビジネスルールに関わる処理はServiceで行う。業務データへのアクセスは、RepositoryまたはO/R Mapperに委譲する。
- ServiceからControllerに返却するデータ(クライアントへレスポンスするデータ)に対する値の変換処理(型変換、形式変換など)は、Serviceではなく、Controller側(Viewクラスなど)で行う。
- トランザクション境界を宣言する。データの一貫性を保障する必要がある処理(主にデータの更新処理)を行う業務ロジックの場合、トランザクション境界を宣言する。データの参照処理の場合でも業務要件によっては、トランザクション管理が必要になる場合もあるので、その場合は、トランザクション境界を宣言する。トランザクション境界は、原則Serviceに設ける。アプリケーション層(Web層)にトランザクション境界が設けられている場合、業務ロジックの抽出が正しく行われていない可能性があるので、見直しを行うこと。
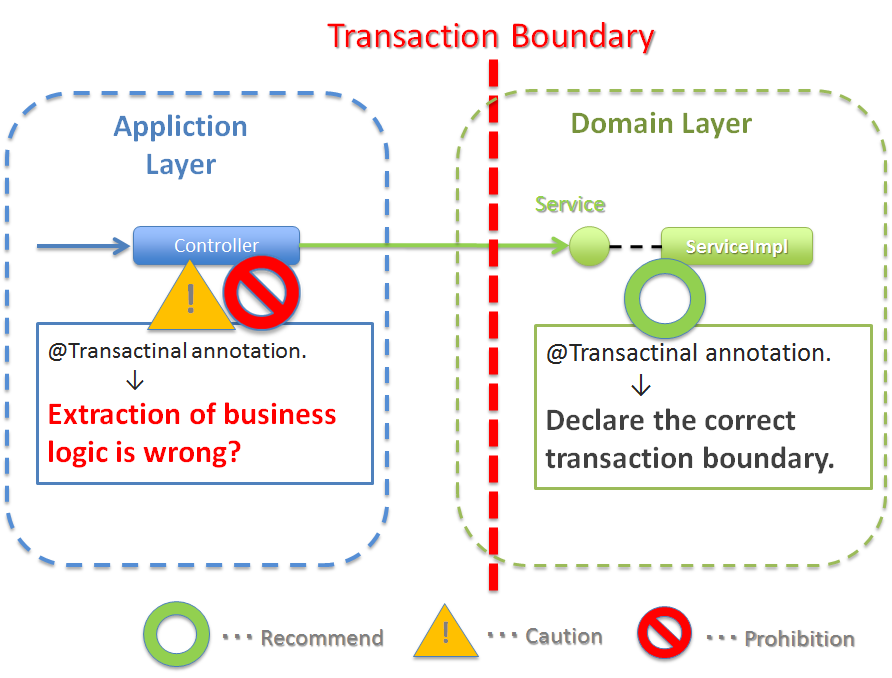
詳細は、トランザクション管理についてを参照されたい。
4.1.5.2. Serviceのクラス構成¶
@Serviceアノテーションが付与されたPOJO(Plain Old Java Object)のことを、ServiceクラスおよびSharedServiceクラスと定義しているが、メソッドのシグネチャを限定するようなインタフェースや、基底クラスを作成することを、禁止しているわけではない。
項番 クラス 役割 依存関係に関する注意点
Serviceクラス
- 他のServiceクラスのメソッドを呼び出すことは、原則禁止とする(※図中1-1)。他のServiceと処理を共有したい場合は、SharedServiceクラスのメソッドを作成し、呼び出すようにすることを推奨する。
- Serviceクラスのメソッドは、複数のControllerから呼び出してもよい(※図中1-2)。ただし、呼び出し元のControllerによって、処理分岐が必要になる場合は、Controller毎に、Serviceクラスのメソッドを作成することを推奨する。その上で共通的な処理は、SharedServiceクラスのメソッドを作成し呼び出すようにする。
2 SharedServiceクラス
- 他のSharedServiceクラスのメソッドを呼び出してもよいが(※図中2-1)、 呼び出し階層が複雑にならないように考慮すること。 呼び出し階層が複雑になると保守性が低下する危険性が高まるので注意が必要。
- ControllerからSharedServiceクラスのメソッドを呼び出してもよい(※図中2-2)が、トランザクション管理の観点で問題がない場合に限る。直接呼び出した場合に、トランザクション管理の観点で問題がある場合は、Serviceクラスにメソッドを用意し、適切なトランザクション管理が行われるようにすること。
- SharedServiceクラスからServiceクラスのメソッドを呼び出すことは禁止する(※図中2-3)。
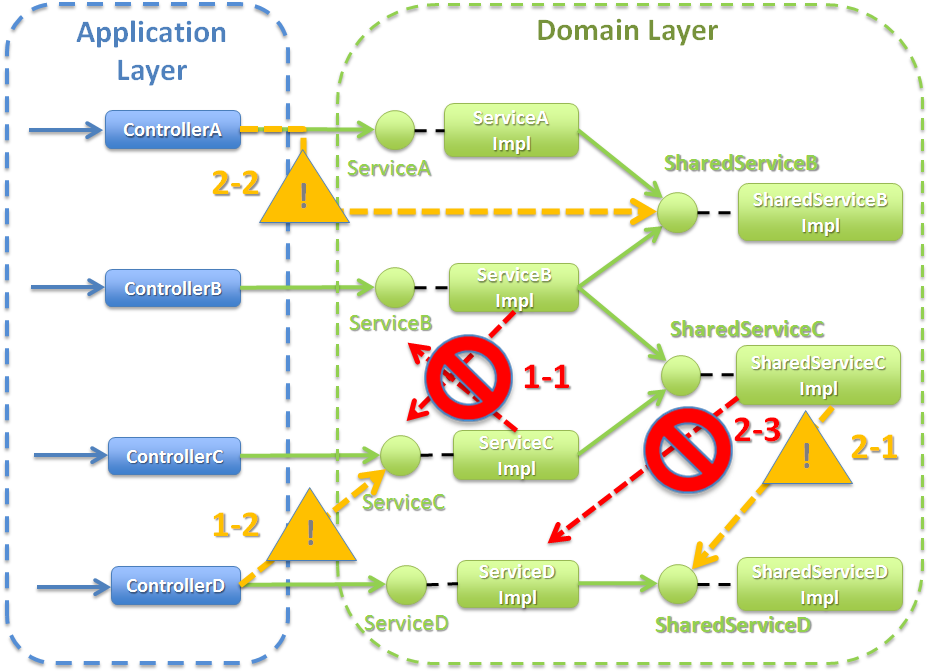
4.1.5.2.2. Serviceクラスから、別のServiceクラスの呼び出しを禁止する理由について¶
項番 発生しうる状況
4.1.5.2.3. メソッドのシグネチャを限定するようなインタフェースや基底クラスについて¶
Note
大規模開発において、サービスイン後の保守性等を考慮して業務ロジックの作りを合わせておきたい場合や、開発者のひとりひとりのスキルがあまり高くない場合などの状況下では、 シグネチャを限定するようなインタフェースを設けることも、選択肢の一つとして考えてもよい。
本ガイドラインでは、シグネチャを限定するようなインタフェースを作成することは、特に推奨していないが、 プロジェクトの特性を加味して、どのようなアーキテクチャにするか決めて頂きたい。
4.1.5.3. Serviceの作成単位¶
Serviceの作成単位は主に以下の3パターンとなる。
項番 単位 作成方法 特徴
3 Warning
Serviceの作成単位については、開発するアプリケーションの特性や開発体制などを加味して決めて頂きたい。
また、提示した3つの作成パターンの どれか一つのパターンに絞る必要はない。 無秩序にいろいろな単位のServiceを作成する事は避けるべきだが、 アーキテクトによって方針が示されている状況下においては、併用しても特に問題はない。 例えば、以下のような組み合わせが考えられる。
【組み合わせて使用する場合の例】
- アプリケーションとして重要な業務ロジックについては、Entity毎のSharedServiceクラスとして作成する。
- 画面からのイベントを処理するための業務ロジックについては、Controller毎のServiceクラスとして作成する。
- Controller毎のServiceクラスでは、必要に応じてSharedServiceクラスのメソッドを呼び出す事で業務ロジックを実装する。
Tip
「TERASOLUNA ViSC」を使用する場合は、BLogicは設計書から出力される。
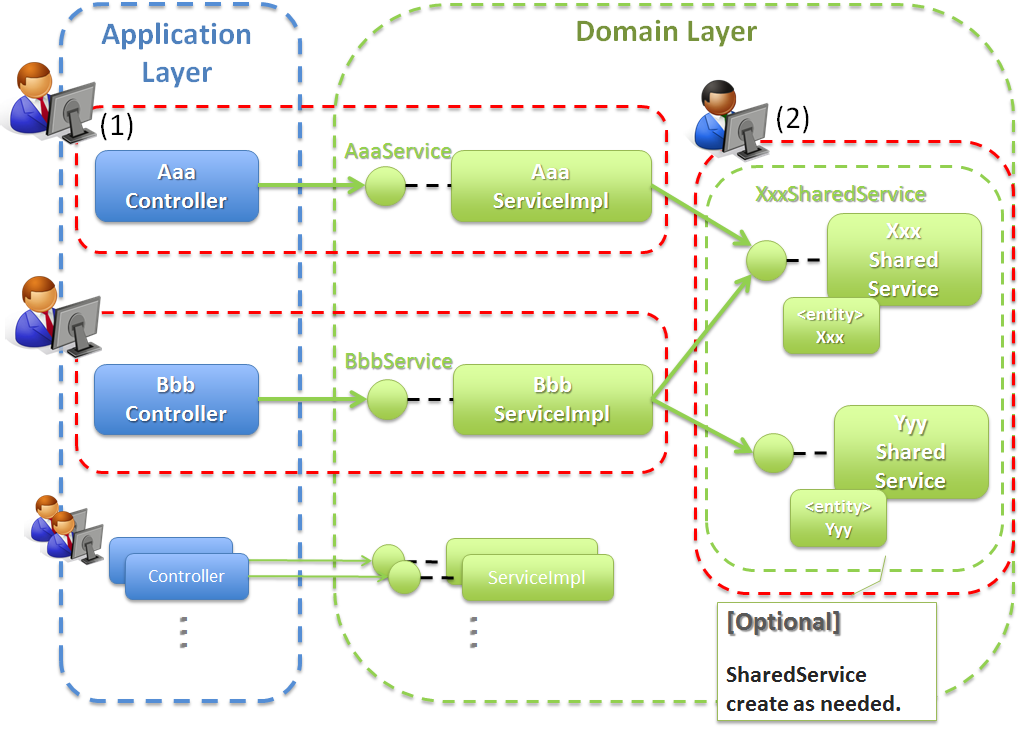
4.1.5.3.1. Entity毎にServiceを作成する際の開発イメージ¶
Entity毎にServiceを作成する場合は、以下のような開発イメージとなる。
Note
Entity毎にServiceを作成する代表的なアプリケーションの例としては、RESTアプリケーションがあげられる。 RESTアプリケーションは、HTTP上に公開するリソースに対してCRUD操作(HTTPのPOST, GET, PUT, DELETE)を提供する事になる。 HTTP上に公開するリソースは、業務データ(Entity)または業務データ(Entity)の一部となる事が多いため、Entity毎にServiceを作成する方法との相性がよい。
RESTアプリケーションの場合は、ユースケースがEntity毎に抽出されることが多い。そのため、ユースケース毎に作成する際の構成イメージと似た構成となる。
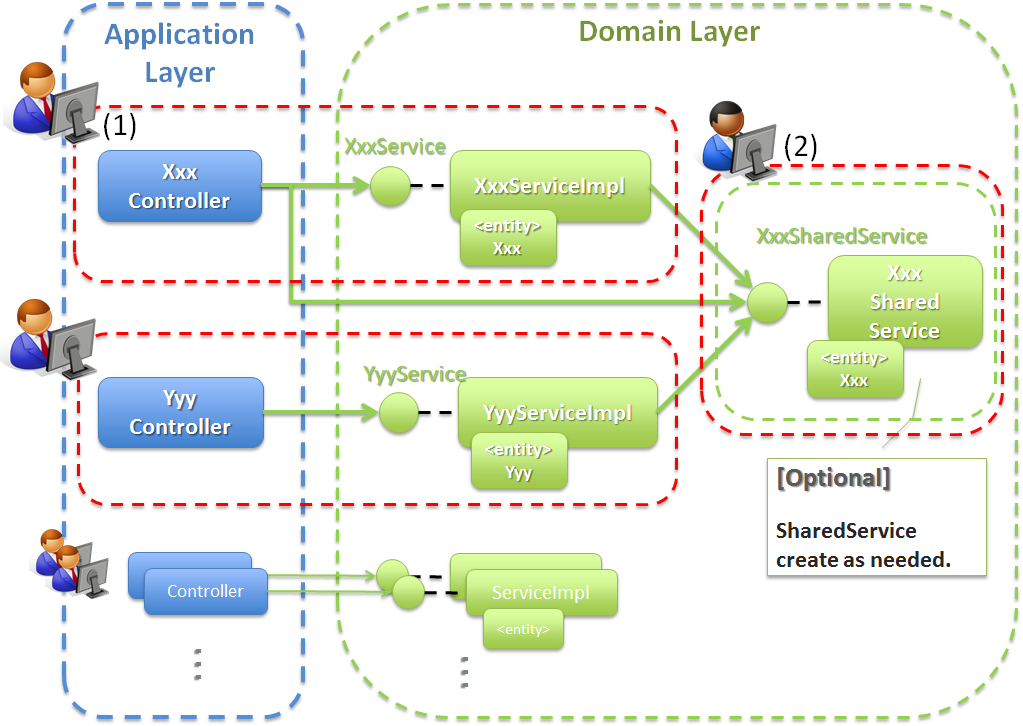
項番 説明
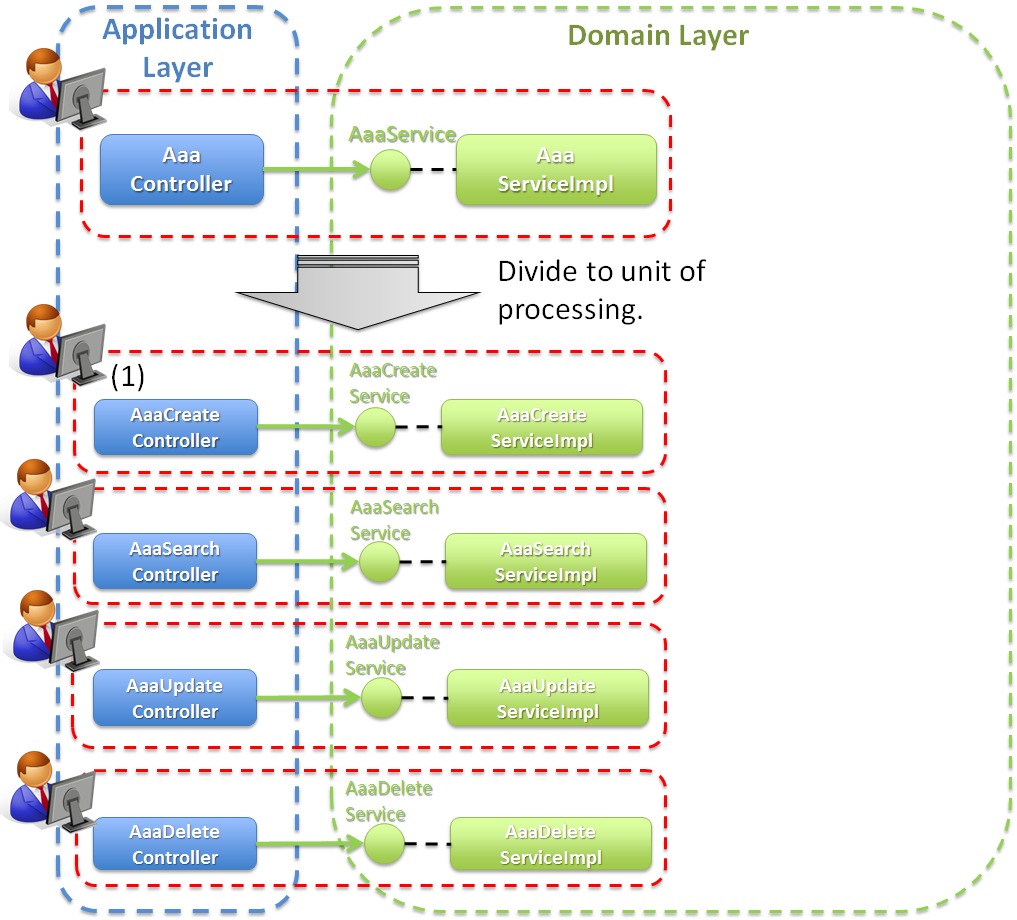
4.1.5.3.2. ユースケース毎に作成する際の開発イメージ¶
項番 説明 Note
ユースケースの規模が大きくなると、一人が担当する開発範囲が大きくなるため、作業分担しづらくなる。 同時に大量の開発者を投入して開発するアプリケーションの場合は、ユースケースを更に分割して、担当者を割り当てる事を検討すること。
項番 説明 Tip
本ガイドライン上で使っている「ユースケース」と「処理」の事を、「ユースケースグループ」と「ユースケース」と呼ぶプロジェクトもある。
4.1.5.3.3. イベント毎に作成する際の開発イメージ¶
イベント毎にService(BLogic)を作成する場合は、以下のような開発イメージとなる。
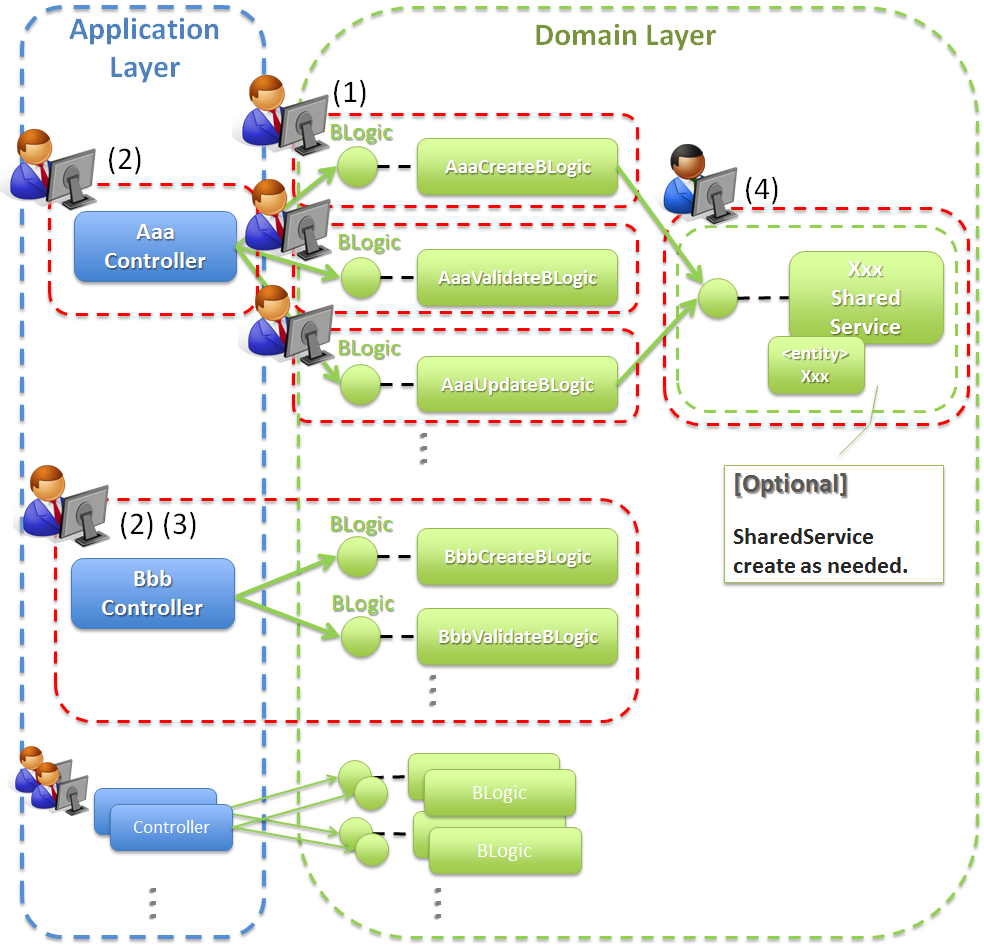
項番 説明 Note
ユースケースの規模が大きくなると、一人が担当する開発範囲が大きくなるため、作業分担しづらくなる。 同時に大量の開発者を投入して開発するアプリケーションの場合は、ユースケースを更に分割して、担当者を割り当てる事を検討すること。

項番 説明
4.1.5.4. Serviceクラスの作成¶
4.1.5.4.1. Serviceクラスの作成方法¶
Serviceクラスを作成する際の注意点を、以下に示す。
- Serviceインタフェースの作成
public interface CartService { // (1) // omitted }
項番 説明
Note
アーキテクチャ観点でのメリット例
- AOPを使う場合に、JDK標準のDynamic proxies機能が使われる。 インタフェースがない場合はSpring Frameworkに内包されているCGLIBが使われるが、finalメソッドに対してAdviceできないなどの制約がある。 詳細は、Spring Reference Documentを参照されたい。
- 業務ロジックをスタブ化しやすくなる。 アプリケーション層とドメイン層を別々の体制で並行して開発する場合は、アプリケーション層を開発するために、Serviceのスタブが必要になるケースがある。 スタブを作成する必要がある場合は、インタフェースを設けておくことを推奨する。
- Serviceクラスの作成
@Service // (1) @Transactional // (2) public class CartServiceImpl implements CartService { // (3) (4) // omitted }<context:component-scan base-package="xxx.yyy.zzz.domain" /> <!-- (1) -->
項番 説明 @Scopeアノテーションを使ってsingleton以外のスコープ(prototype, request, session)にしてはいけない。
Note
クラスに @Transactional アノテーションを付加する理由
トランザクション境界の設定が必須なのは更新処理を含む業務ロジックのみだが、設定漏れによるバグを防ぐ事を目的として、クラスレベルにアノテーションを付与することを推奨している。 もちろん必要な箇所(更新処理を行うメソッド)のみに、
@Transactionalアノテーションを定義する方法を採用してもよい。Note
singleton以外のスコープを禁止する理由
- prototype, request, sessionは、状態を保持するbeanを登録するためのスコープであるため、Serviceクラスに対して使用すべきでない。
- スコープをrequestやprototypeにした場合、DIコンテナによるbeanの生成頻度が高くなるため、性能に影響を与えることがある。
- スコープをrequestやsessionにした場合、Webアプリケーション以外のアプリケーション(例えば、Batchアプリケーションなど)で使用できなくなる。
4.1.5.4.2. Serviceクラスのメソッドの作成方法¶
Serviceクラスのメソッドを作成する際の注意点を、以下に示す。
- Serviceインタフェースのメソッド作成
public interface CartService { Cart createCart(); // (1) (2) Cart findCart(String cartId); // (1) (2) }
- Serviceクラスのメソッドの作成
@Service @Transactional public class CartServiceImpl implements CartService { @Inject CartRepository cartRepository; public Cart createCart() { // (1) (2) Cart cart = new Cart(); // ... cartRepository.save(cart); return cart; } @Transactional(readOnly = true) // (3) public Cart findCart(String cartId) { // (1) (2) Cart cart = cartRepository.findByCartId(cartId); // ... return cart; } }
項番 説明
Warning
参照系の業務ロジックのトランザクション定義について
参照系の業務ロジックの場合、
@Transactional(readOnly = true)を設定を行うことで、 参照系の処理として必要なトランザクション管理が行われるケースがあるが、 JPAを使う場合は「readOnly = true」は意味がないので指定しなくてもよい。 詳細は、IBM DeveloperWorks の記事の 「Listing 7. Using read-only with REQUIRED propagation mode — JPA」辺りを参照されたい。Note
新しいトランザクションを開始する必要がある場合のトランザクション定義について
呼び出し元のメソッドが参加しているトランザクションには参加せず、 新しいトランザクションを開始する必要がある場合は、
@Transactional(propagation = Propagation.REQUIRES_NEW)を設定する。
4.1.5.4.3. Serviceクラスのメソッド引数と返り値について¶
Serviceクラスのメソッド引数と返り値は、以下の点を考慮すること。
java.io.Serializableを実装しているクラス)とする。メソッド引数/返り値となる代表的な型を以下に示す。
- プリミティブ型(
int,longなど)- プリミティブラッパークラス(
java.lang.Integer,java.lang.Longなど)- java標準クラス(
java.lang.String,java.util.Dateなど)- ドメインオブジェクト(Entity、DTOなど)
- 入出力オブジェクト(DTO)
- 上記型のコレクション(
java.util.Collectionの実装クラス)- void
- etc …
Note
入出力オブジェクトとは
- 入力オブジェクトとは、Serviceのメソッドを実行するために必要な入力値をまとめたオブジェクトのことをさす。
- 出力オブジェクトとは、Serviceのメソッドの実行結果(出力値)をまとめたオブジェクトのことをさす。
「TERASOLUNA ViSC」を使用して、業務ロジック(BLogicクラス)を生成する場合、BLogicの引数と返り値には、入出力オブジェクトを使用することになる。
メソッド引数/返り値として禁止するものを以下に示す。
- アプリケーション層の実装アーキテクチャ(Servlet APIやSpringのweb層のAPIなど)に依存するオブジェクト(
javax.servlet.http.HttpServletRequest、javax.servlet.http.HttpServletResponse、javax.servlet.http.HttpSession、org.springframework.http.server.ServletServerHttpRequestなど)- アプリケーション層のモデル(Form,DTOなど)
java.util.Mapの実装クラスNote
禁止する理由
- アプリケーション層の実装アーキテクチャに依存するオブジェクトを許可してしまうと、アプリケーション層とドメイン層が密結合になってしまう。
java.util.Mapは、インタフェースとして汎用性が高すぎるため、メソッドの引数や返り値に使うと、 どのようなオブジェクが格納されているかわかりづらい。 また、値の管理がキー名で行われるため、以下の問題が発生しやすくなる。
- 値を設定する処理と値を取得する処理で異なるキー名を指定してしまい、値が取得できない。
- キー名の変更した場合の影響範囲の把握が困難になる。
アプリケーション層とドメイン層で同じDTOを共有する場合の方針を、以下に示す。
- ドメイン層のパッケージに属するDTOとして作成し、アプリケーション層で利用する。
Warning
アプリケーション層のFormやDTOを、ドメイン層で利用してはいけない。
4.1.5.6. 処理の実装¶
ServiceおよびSharedServiceのメソッドで実装する処理について説明する。
ServiceおよびSharedServiceでは、アプリケーションで使用する業務データの取得、更新、整合性チェックおよびビジネスルールに関わる各種ロジックの実装を行う。
以下に、代表的な処理の実装例について説明する。
4.1.5.6.1. 業務データを操作する¶
業務データ(Entity)の取得、更新の実装例については、
- JPAを使う場合は、データベースアクセス(JPA編)
- Mybatis2を使う場合は、データベースアクセス(Mybatis2編)
を参照されたい。
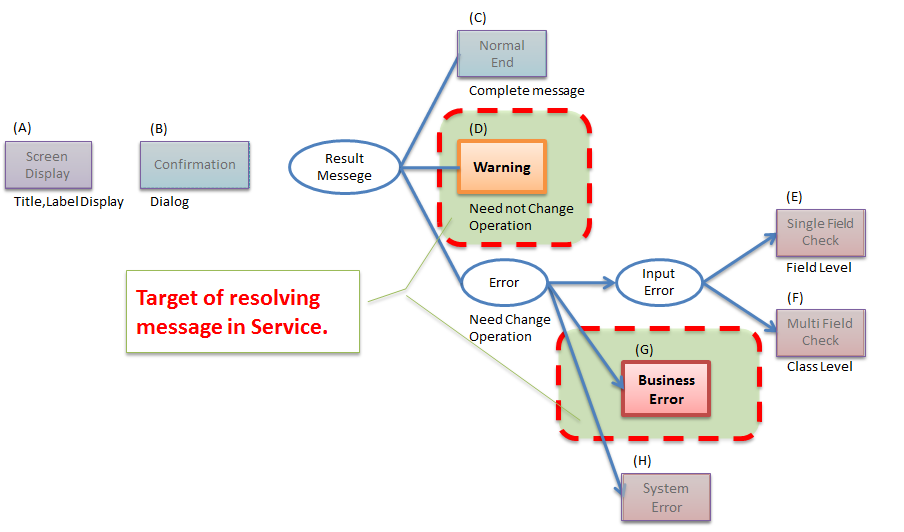
4.1.5.6.2. メッセージを返却する¶
Note
メッセージの解決について
Serviceで解決するのは、メッセージ文言ではなく、メッセージ文言を組み立てるために必要な情報(メッセージコード、メッセージ埋め込み値)の解決であるという点を補足しておく。
詳細な実装方法は、
を参照されたい。
4.1.5.6.3. 警告メッセージを返却する¶
org.terasoluna.fw.common.message.ResultMessages)を用意している。- DTOの作成
public class OrderResult implements Serializable { private ResultMessages warnMessages; private Order order; // omitted }
- Serviceクラスのメソッドの実装
下記の例では、注文した商品の中に取り寄せ商品が含まれているため、分割配達となる可能性がある旨を警告メッセージとして表示する場合の実装例である。
public OrderResult submitOrder(Order order) { // omitted boolean hasOrderProduct = orderRepository.existsByOrderProduct(order); // (1) // omitted Order order = orderRepository.save(order); // omitted ResultMessages warnMessages = null; // (2) if(hasOrderProduct) { warnMessages = ResultMessages.warn().add("w.xx.xx.0001"); } // (3) OrderResult orderResult = new OrderResult(); orderResult.setOrder(order); orderResult.setWarnMessages(warnMessages); return orderResult; }
項番 説明 hasOrderProductにtrueが設定される。Orderオブジェクトと警告メッセージを一緒に返却するために、OrderResultというDTOにオブジェクトを格納して返却している。
4.1.5.6.4. 業務エラーを通知する¶
- 旅行を予約する際に予約日が期限を過ぎている場合
- 商品を注文する際に在庫切れの場合
- etc …
org.terasoluna.fw.common.exception.BusinessException)を用意している。Note
ビジネス例外を非検査例外にする理由
ビジネス例外は、Controllerでハンドリングが必要になるため、本来は検査例外にした方がよい。 しかし、本ガイドラインでは、設定漏れによるバグを防ぐ事を目的として、デフォルトでロールバックされる java.lang.RuntimeException のサブクラスとすることを推奨する。 もちろん検査例外のサブクラスとしてビジネス例外を作成し、ビジネス例外クラスをロールバック対象として定義する方法を採用してもよい。
// omitted if(currentDate.after(reservationLimitDate)) { // (1) throw new BusinessException(ResultMessages.error().add("e.xx.xx.0001")); } // omitted
項番 説明 旅行を予約する際に、予約日が期限を過ぎているので、ビジネス例外をスローしている。
例外ハンドリング全体の詳細は、例外ハンドリングを参照されたい。
4.1.5.6.5. システムエラーを通知する¶
- 事前に存在しているはずのマスタデータ、ディレクトリ、ファイルなどが存在しない場合
- 利用しているライブラリのメソッドから発生する検査例外のうち、システム異常に分類される例外を補足した場合
- etc …
org.terasoluna.fw.common.exception.SystemException)を用意している。@Transactinalアノテーションのデフォルトのロールバック対象が、java.lang.RuntimeExceptionのためである。ItemMaster itemMaster = itemMasterRepository.findOne(itemCode); if(itemMaster == null) { // (1) throw new SystemException("e.xx.fw.0001", "Item master data is not found. item code is " + itemCode + "."); }
項番 説明 事前に存在しているはずのマスタデータがないので、システム例外をスローしている。(ロジックで、システム異常を検知した場合の実装例)
下記の例では、ファイルコピー時のIOエラーをシステムエラーとして通知する際の実装例である。
// ... try { FileUtils.copy(srcFile, destFile); } catch(IOException e) { // (1) throw new SystemException("e.xx.fw.0002", "Failed file copy. src file '" + srcFile + "' dest file '" + destFile + "'.", e); }
項番 説明
Note
データアクセスエラーの扱いについて
業務ロジック実行中に、RepositoryやO/R Mapperでデータアクセスエラーが発生した場合、
org.springframework.dao.DataAccessExceptionのサブクラスに変換されてスローされる。 基本的には、業務ロジックではキャッチせず、アプリケーション層でエラーハンドリングすればよいが、 一意制約違反などの一部のエラーについては、業務要件によっては、業務ロジックでハンドリングする必要がある。 詳細は、データベースアクセス(共通編)を参照されたい。
4.1.6. トランザクション管理について¶
データの一貫性を保証する必要がある処理ではトランザクションの管理が必要となる。
4.1.6.1. トランザクション管理の方法¶
トランザクションの管理方法はいろいろあるが、本ガイドラインでは、Spring Frameworkから提供されている「宣言型トランザクション管理」を利用することを推奨する。
4.1.6.1.1. 宣言型トランザクション管理¶
「宣言型トランザクション管理」では、トランザクション管理に必要な情報を以下に2つの方法で宣言することができる。
- XML(bean定義ファイル)で宣言する。
- アノテーション(@Transactional)で宣言する。(推奨)
Spring Frameworkから提供されている「宣言型トランザクション管理」の詳細については、Spring Reference Documentを参照されたい。
Note
「アノテーションで指定する」方法を推奨する理由
- ソースコードを見ただけで、どのようなトランザクション管理が行われるかについて、把握することができる。
- XMLにトランザクション管理するためのAOPの設定が不要であり、XMLがシンプルになる。
4.1.6.1.2. 「宣言型トランザクション管理」で必要となる情報¶
@Transactionalアノテーションを指定する。@Transactionalアノテーションの属性で指定する。
項番 属性名 説明 1 propagation 2 isolation 3 timeout 4 readOnly 5 rollbackFor 6 rollbackForClassName 7 noRollbackFor 8 noRollbackForClassName
Note
@Transactionalアノテーションを指定する場所
クラスまたはクラスのメソッドに指定することを推奨する。 インタフェースまたはインタフェースのメソッドでない点が、ポイント。 理由は、Spring Reference Documentの2個めのTipsを参照されたい。
Warning
例外発生時のrollbackとcommitのデフォルト動作
rollbackForおよびnoRollbackForを指定しない場合、Spring Frameworkは、以下の動作となる。
- 非検査例外クラス(java.lang.RuntimeExceptionおよびjava.lang.Error)またはそのサブクラスの例外が発生した場合は、rollbackする。
- 検査例外クラス(java.lang.Exception)またはそのサブクラスの例外が発生した場合は、commitする。(注意が必要)
Note
@Transactionalアノテーションのvalue属性について
@Transactionalアノテーションにはvalue属性があるが、これは複数のTransaction Managerを宣言した際に、どのTransaction Managerを使うのかを指定する属性である。 Transaction Managerが一つの場合は指定は不要である。 複数のTransaction Managerを使う必要がある場合は、Spring Reference Documentを参照されたい。Note
主要DBのisolationのデフォルトについて
主要DBのデフォルトの独立性レベルは、以下の通りである。
- Oracle : READ_COMMITTED
- DB2 : READ_COMMITTED
- PostgreSQL : READ_COMMITTED
- SQL Server : READ_COMMITTED
- MySQL : REPEATABLE_READ
4.1.6.1.3. トランザクションの伝播¶
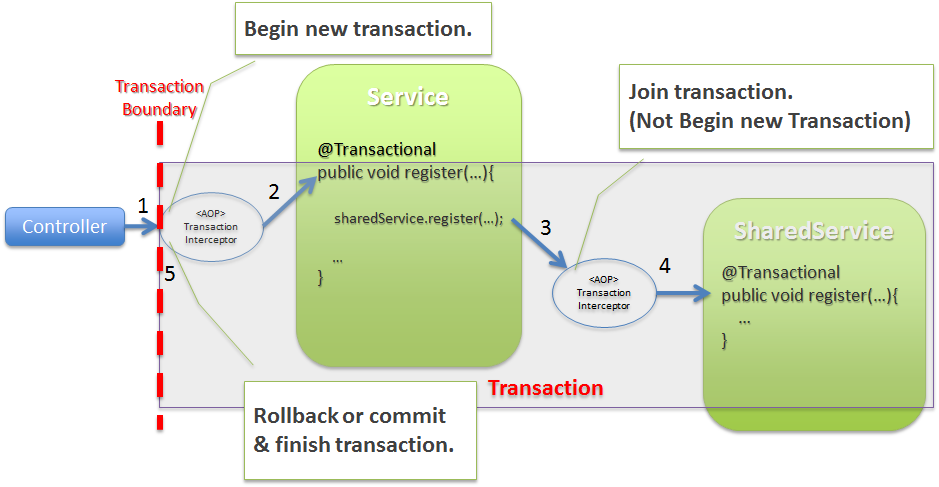
- Controllerからトランザクション管理対象のServiceのメソッドを呼び出す。
この時点で開始されているトランザクションは存在しないため、
TransactionInterceptorによってトランザクションが開始される。 TransactionInterceptorは、トランザクション開始した後に、トランザクション管理対象のメソッドを呼び出す。- Serviceからトランザクション管理対象の
SharedServiceのメソッドを呼び出す。 この時点で開始済みのトランザクションが存在しているため、TransactionInterceptorは、新たにトランザクションは開始せず、開始済みのトランザクションに参加する。 TransactionInterceptorは、開始済みのトランザクションに参加した後に、トランザクション管理対象のメソッドを呼び出す。TransactionInterceptorは、処理結果に応じてコミットまたはロールバックを行い、トランザクションを終了する。
Note
org.springframework.transaction.UnexpectedRollbackExceptionが発生する理由
トランザクションの伝播方法を「REQUIRED」にした場合、物理的なトランザクションは一つだが、Spring Frameworkでは内部的なトランザクション制御境界が設けられている。
上記例だと、SharedServiceが呼び出された際に実行されるTransactionInterceptorが、内部的なトランザクション制御を行っている。
そのため、SharedServiceでロールバック対象の例外が発生した場合、TransactionInterceptorによって、
トランザクションはロールバック状態(rollback-only)に設定され、トランザクションをコミットすることはできなくなる。
この状態でトランザクションのコミットを行おうとすると、Spring Frameworkは、UnexpectedRollbackExceptionを発生させ、トランザクション制御に矛盾が発生している事を通知してくれる。
UnexpectedRollbackExceptionが発生した場合、rollbackForおよびnoRollbackForの定義に、矛盾がないか、確認すること。
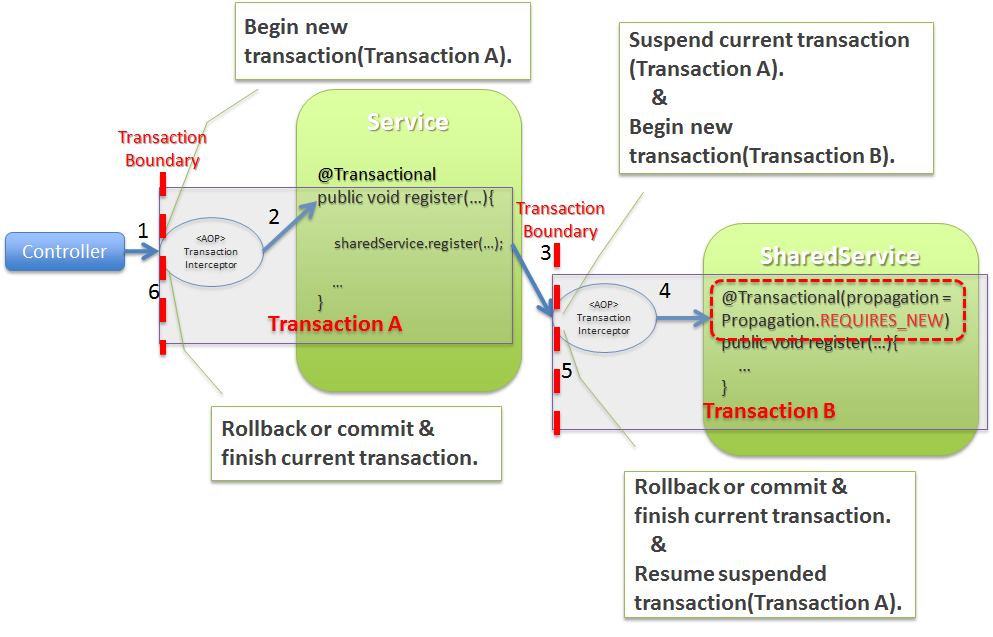
- Controllerからトランザクション管理対象のServiceのメソッドを呼び出す。この時点で開始されているトランザクションは存在しないため、
TransactionInterceptorによってトランザクションが開始される(ここで開始したトランザクションを以降「Transaction A」と呼ぶ)。 TransactionInterceptorは、トランザクション(Transaction A)を開始した後に、トランザクション管理対象のメソッドを呼び出す。- Serviceからトランザクション管理対象の
SharedServiceのメソッドを呼び出す。この時点で開始済みのトランザクション(Transaction A)が存在しているが、トランザクションの伝播方法が「REQUIRES_NEW」なのでTransactionInterceptorによって新しいトランザクションが開始される(ここで開始したトランザクションを以降「Transaction B」と呼ぶ)。この時点で「Transaction A」のトランザクションは、中断され再開待ちの状態となる。 TransactionInterceptorは、トランザクション(Transaction B)を開始した後に、トランザクション管理対象のメソッドを呼び出す。TransactionInterceptorは、処理結果に応じてコミットまたはロールバックを行い、トランザクション(Transaction B)を終了する。 この時点で、「Transaction A」のトランザクションが再開され、アクティブな状態になる。TransactionInterceptorは、処理結果に応じてコミットまたはロールバックを行い、トランザクション(Transaction A)を終了する。
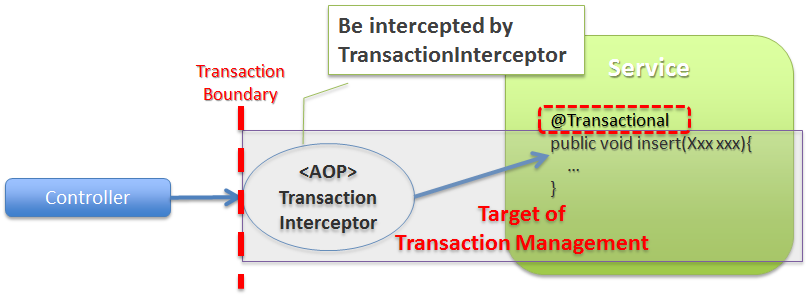
4.1.6.1.4. トランザクション管理対象となるメソッドの呼び出し方¶
- トランザクション管理対象となるメソッドの呼び出し方
- トランザクション管理対象にならないメソッドの呼び出し方
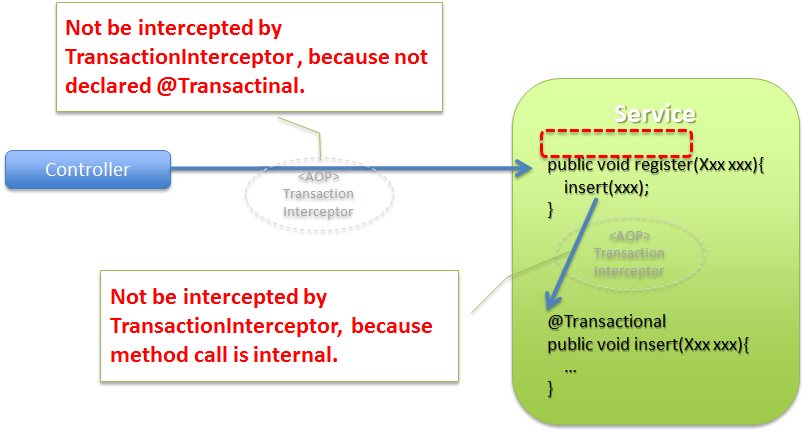
Note
内部呼び出しをトランザクション管理対象にしたい場合
AOPモードを
"aspectj"にすることで、内部呼び出しをトランザクション管理対象にすることができる。 ただし、内部呼び出しもトランザクション管理対象にしてしまうと、トランザクション管理の経路が複雑になる可能性があるので、 基本的にはAOPモードはデフォルトの"proxy"を使用することを推奨する。
4.1.6.2. トランザクション管理を使うための設定について¶
トランザクション管理を使うために必要な設定について説明する。
4.1.6.2.1. PlatformTransactionManagerの設定¶
PlatformTransactionManagerのbeanを設定する必要がある。xxx-env.xml
以下に、DataSourceから取得されるJDBCコネクションの機能を使って、トランザクションを管理する場合の設定例を示す。
<!-- (1) --> <bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"> <property name="dataSource" ref="dataSource" /> </bean>
項番 説明 PlatformTransactionManagerの実装クラスを指定する。idは「transactionManager」としておくことを推奨する。
Note
複数DB(複数リソース)に対するトランザクション管理(グローバルトランザクションの管理)が必要な場合
org.springframework.transaction.jta.JtaTransactionManagerを利用し、アプリケーションサーバから提供されているJTAの機能を使って、トランザクション管理を行う必要がある。- WebSphere、Oracle WebLogic Server、Oracle OC4JでJTAを使う場合、<tx:jta-transaction-manager/> を指定することで、 アプリケーションサーバ用に拡張された
JtaTransactionManagerが、自動的で設定される。
Spring Frameworkから提供されているPlatformTransactionManagerの実装クラス¶ 項番 クラス名 説明
java.sql.Connection)のAPIを呼び出して、トランザクションを管理するための実装クラス。Mybatisや、JdbcTemplateを使う場合は、本クラスを使用する。
javax.persistence.EntityTransaction)のAPIを呼び出して、トランザクションを管理するための実装クラス。JPAを使う場合は、本クラスを使用する。
javax.transaction.UserTransaction)のAPIを呼び出してトランザクションを管理するための実装クラス。アプリケーションサーバから提供されているJTS(Java Transaction Service)を利用して、リソース(データベース/メッセージングサービス/汎用EIS(Enterprise Information System)など)とのトランザクションを管理する場合は、本クラスを使用する。複数のリソースに対する操作を同一トランザクションで行う必要がある場合は、JTAを利用して、リソースとのトランザクションを管理する必要がある。
4.1.6.2.2. @Transactionalを有効化するための設定¶
@Transactionalアノテーションを使った「宣言型トランザクション管理」を使って、トランザクション管理することを推奨している。@Transactionalアノテーションを使うために、必要な設定について説明する。xxx-domain.xml
<tx:annotation-driven /> <!-- (1) -->
項番 説明 <tx:annotation-driven>要素をXML(bean定義ファイル)に追加することで、 @Transactionalアノテーションを使ったトランザクション境界の指定が有効となる。
4.1.6.2.3. <tx:annotation-driven>要素の属性について¶
<tx:annotation-driven>にはいくつかの属性が指定でき、デフォルトの振る舞いを拡張することができる。
xxx-domain.xml
<tx:annotation-driven transaction-manager="txManager" mode="aspectj" proxy-target-class="true" order="0" />
項番 属性 説明 1 transaction-manager PlatformTransactionManagerのbeanを指定する。省略した場合「transactionManager」というbean名で登録されているbeanが使用される。2 mode AOPのモードを指定する。省略した場合、 "proxy"となる。"aspectj"を指定できるが、原則デフォルトの"proxy"を使う。3 proxy-target-class proxyのターゲットをクラスに限定するかを指定するフラグ(mode=”proxy”の場合のみ、有効な設定)。省略した場合「false」となる。
- false の場合、対象がインタフェースを実装している場合は、JDK標準のDynamic proxies機能によってproxyされ、 インタフェースを実装していない場合はSpring Frameworkに内包されているGCLIBの機能によってproxyされる。
- true の場合、インタフェースの実装有無に関係なく、GCLIBの機能によってproxyされる。
4 order AOPでAdviceされる順番(優先度)を指定する。省略した場合「最後(もっとも低い優先度)」となる。
4.1.7. Appendix¶
4.1.7.1. トランザクション管理の落とし穴について¶
詳細は、IBM DeveloperWorksの記事を参照されたい。
4.1.7.2. プログラマティックにトランザクションを管理する方法¶
本ガイドラインでは、「宣言型トランザクション管理」を推奨しているが、プログラマティックにトランザクションを管理することもできる。 詳細については、Spring Reference Documentを参照されたい。
4.1.7.3. シグネチャを制限するインタフェースおよび基底クラスの実装サンプル¶
- シグネチャを限定するようなインタフェース
// (1) public interface BLogic<I, O> { O execute(I input); }
項番 説明
定型的な共通処理をServiceに盛り込む場合、ビジネスロジックの処理フローを統一したい場合に、メソッドのシグネチャを限定するような基底クラスを作成することがある。
- シグネチャを限定するような基底クラス
// (2) @Service @Transactional public abstract class AbstractBLogic<I, O> implements BLogic<I, O> { public O execute(I input){ try{ // omitted // (3) preExecute(input); // (4) O output = doExecute(input); // omitted return output; } finally { // omitted } } protected abstract void preExecute(I input); protected abstract O doExecute(I input); }
項番 説明
以下に、シグネチャを限定するような、基底クラスを継承する場合の、サンプルを示す。
- BLogicクラス(Service)
// (5) public interface XxxBLogic extends BLogic<XxxInput, XxxOutput> { }
項番 説明
項番 説明
- Controller
// (8) @Inject XxxBLogic xxxBLogic; public String reserve(XxxForm form, RedirectAttributes redirectAttributes) { XxxInput input = new XxxInput(); // omitted // (9) XxxOutput output = xxxBlogic.execute(input); // omitted redirectAttributes.addFlashAttribute(output.getTourReservation()); return "redirect:/xxx?complete"; }
項番 説明