5.1. データベースアクセス(共通編)¶
Caution
本バージョンの内容は既に古くなっています。最新のガイドラインはこちらからご参照ください。
Todo
TBD
本章では以下の内容について、現在精査中である。
- 複数データソースについて具体的な内容は、Overviewの複数データソースについておよびHow to extendsの複数データソースについてを参照されたい。
- JPA利用時の一意制約エラー及び悲観排他エラーのハンドリング方法について具体的な内容は、Overviewの例外ハンドリングについてを参照されたい。
5.1.1. Overview¶
5.1.1.1. JDBC DataSourceについて¶
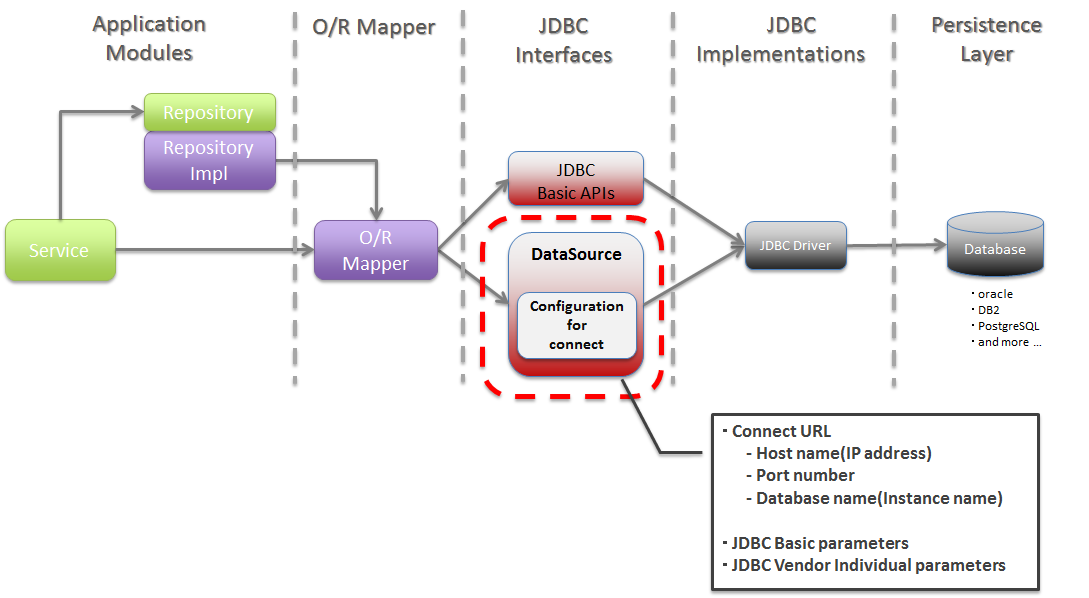
Picture - About JDBC DataSource
5.1.1.1.1. アプリケーションサーバ提供のJDBCデータソース¶
アプリケーションサーバから提供されているデータソース¶ 項番 アプリケーションサーバ 参照ページ
Apache Tomcat 7
Oracle WebLogic Server 12c Oracle WebLogic Server Product Documentationを参照されたい。
IBM WebSphere Application Server Version 8.5 WebSphere Application Server Online information centerを参照されたい。
Resin 4.0 Resin Documentationを参照されたい。
5.1.1.1.2. OSS/Third-Partyライブラリ提供のJDBCデータソース¶
OSS/Third-Partyライブラリから提供されているJDBCデータソース¶ 項番 ライブラリ名 説明
Apache Commons DBCP Apache Commons DBCPを参照されたい。
5.1.1.1.3. Spring Framework提供のJDBCデータソース¶
5.1.1.2. トランザクションの管理方法について¶
5.1.1.3. トランザクション境界/属性の宣言について¶
@Transactionalアノテーションを指定することで実現する。5.1.1.4. データの排他制御について¶
5.1.1.5. 例外ハンドリングについて¶
java.sql.SQLException)や、O/R Mapper固有の例外を、Spring Frameworkから提供しているデータアクセス例外(org.springframework.dao.DataAccessExceptionのサブクラス)に変換する機能がある。DataAccessExceptionをcatchするのではなく、エラー内容を通知するサブクラスの例外をcatchすること。
ハンドリングする可能性があるDBアクセス例外のサブクラス¶ 項番 クラス名 説明
Note
O/R MapperにMybatisを使用して楽観ロックを実現する場合は、ServiceやRepositoryの処理として楽観ロック処理を実装する必要がある。
本ガイドラインでは、楽観ロックに失敗したことを、Controllerに通知する方法として、
OptimisticLockingFailureExceptionおよびその子クラスの例外を発生させることを推奨する。理由は、アプリケーション層の実装(Controllerの実装)を、使用するO/R Mapperに依存させないためである。
Todo
JPA(Hibernate)を使用すると、現状意図しないエラーとなることが発覚している。
- 一意制約違反が発生した場合、
DuplicateKeyExceptionではなく、org.springframework.dao.DataIntegrityViolationExceptionが発生する。- 悲観ロックに失敗した場合、
PessimisticLockingFailureExceptionではなく、org.springframework.dao.UncategorizedDataAccessExceptionの子クラスが発生する。悲観エラー時に発生する
UncategorizedDataAccessExceptionは、システムエラーに分類される例外なので、アプリケーションでハンドリングすることは推奨されないが、最悪ハンドリングを行う必要があるかもしれない。 原因例外には、悲観ロックエラーが発生したことを通知する例外が格納されているので、ハンドリングできる。⇒継続調査。
現状以下の動作となる。
- PostgreSQL + for update nowait
- org.springframework.orm.hibernate3.HibernateJdbcException
- Caused by: org.hibernate.PessimisticLockException
- Oracle + for update
- org.springframework.orm.hibernate3.HibernateSystemException
- Caused by: Caused by: org.hibernate.dialect.lock.PessimisticEntityLockException
- Caused by: org.hibernate.exception.LockTimeoutException
- Oracle / PostgreSQL + 一意制約
- org.springframework.dao.DataIntegrityViolationException
- Caused by: org.hibernate.exception.ConstraintViolationException
下記は、一意制約違反を、ビジネス例外として扱う実装例である。
try { accountRepository.saveAndFlash(account); } catch(DuplicateKeyException e) { // (1) throw new BusinessException(ResultMessages.error().add("e.xx.xx.0002"), e); // (2) }
項番 説明 e) をビジネス例外に指定すること。
5.1.1.6. 複数データソースについて¶
複数のデータソースが必要になるう代表的なケース¶ 項番 ケース 例 特徴
データ(テーブル)の分類毎にデータベースやスキーマがわかれている場合。 顧客情報を保持するテーブル群と請求情報を保持するテーブル群が別々のデータベースやスキーマに格納されている場合など。 処理で扱うデータは決まっているので、静的に使用するデータソースを決定することができる。
利用者(ログインユーザ)によって使用するデータベースやスキーマが分かれている場合。 利用者の分類毎にデータベースやスキーマがわかれている場合など(マルチテナント等)。 利用者によって使用するデータソースが異なるため、動的に使用するデータソースを決定する必要がある。 Todo
TBD
今後、以下の内容を追加する予定である。
- 概念レベルのイメージ図
- 上記2ケースについての詳細。 特に、(1)のケースは、処理パターン(複数のデータソースに対して更新あり、更新は1つのデータソース、参照のみ、同時アクセスはなしなど)によってトランザクション管理の方法がかわると思うので、その辺りを中心にブレークダウンする予定である。
5.1.2. How to use¶
5.1.2.1. データソースの設定¶
5.1.2.1.1. アプリケーションサーバで定義したDataSourceを使用する場合の設定¶
xxx-context.xml(Tomcatの設定ファイル)<!-- (1) --> <Resource type="javax.sql.DataSource" name="jdbc/SampleDataSource" driverClassName="org.postgresql.Driver" url="jdbc:postgresql://localhost:5432/terasoluna" username="postgres" password="postgres" defaultAutoCommit="false" /> <!-- (2) -->
xxx-env.xml
<jee:jndi-lookup id="dataSource" jndi-name="jdbc/SampleDataSource" /> <!-- (3) -->
項番 属性名 説明 - データソースを定義する。 type リソースの種類を指定する。 javax.sql.DataSourceを指定する。name リソース名を指定する。ここで指定した名前がJNDI名となる。 driverClassName JDBCドライバクラスを指定する。例では、PostgreSQLから提供されているJDBCドライバクラスを指定する。 url 接続URLを指定する。 【環境に合わせて変更が必要】 username 接続ユーザ名を指定する。【環境に合わせて変更が必要】 password 接続ユーザのパスワードを指定する。【環境に合わせて変更が必要】 defaultAutoCommit 自動コミットフラグのデフォルト値を指定する。falseを指定する。トランザクション管理下であれば強制的にfalseになる。 - - データソースのJNDI名を指定する。Tomcatの場合は、データソース定義時のリソース名「(1)-name」に指定した値を指定する。
5.1.2.1.2. Bean定義したDataSouceを使用する場合の設定¶
xxx-env.xml
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close"> <!-- (1) (8) --> <property name="driverClassName" value="org.postgresql.Driver" /> <!-- (2) --> <property name="url" value="jdbc:postgresql://localhost:5432/terasoluna" /> <!-- (3) --> <property name="username" value="postgres" /> <!-- (4) --> <property name="password" value="postgres" /> <!-- (5) --> <property name="defaultAutoCommit" value="false"/> <!-- (6) --> <!-- (7) --> </bean>
項番 説明 データソースの実装クラスを指定する。例では、Apache Commons DBCPから提供されているデータソースクラス( org.apache.commons.dbcp.BasicDataSource)を指定する。JDBCドライバクラスを指定する。例では、PostgreSQLから提供されているJDBCドライバクラスを指定する。 接続URLを指定する。 【環境に合わせて変更が必要】 接続ユーザ名を指定する。【環境に合わせて変更が必要】 接続ユーザのパスワードを指定する。【環境に合わせて変更が必要】 自動コミットフラグのデフォルト値を指定する。falseを指定する。トランザクション管理下であれば、強制的にfalseになる。 PropertyPlaceholderConfigurerを参照されたい。
5.1.2.2. トランザクション管理を有効化するための設定¶
5.1.2.3. JDBCのDebug用ログの設定¶
Warning
本設定はDebug用の設定なので、性能試験および商用環境にリリースする資材には、設定しないようにすること。
5.1.2.3.1. log4jdbc提供のデータソースの設定¶
xxx-env.xml
<jee:jndi-lookup id="dataSourceSpied" jndi-name="jdbc/SampleDataSource" /> <!-- (1) --> <bean id="dataSource" class="net.sf.log4jdbc.Log4jdbcProxyDataSource"> <!-- (2) --> <constructor-arg ref="dataSourceSpied" /> <!-- (3) --> </bean>
項番 説明 データソースの実体を定義する。例では、アプリケーションサーバからJNDI経由で取得したデータソースを使用している。 log4jdbcより提供されている net.sf.log4jdbc.Log4jdbcProxyDataSourceを指定する。データソースの実体となるbeanを、コンストラクタに指定する。 Warning
性能試験及び商用環境にリリースする場合、データソースとしてLog4jdbcProxyDataSourceは使用しないこと。
具体的には、(2)と(3)の設定を外し、
"dataSourceSpied"のbean名を"dataSource"に変更する。
5.1.2.3.2. log4jdbc用ロガーの設定¶
logback.xml
<!-- (1) --> <logger name="jdbc.sqltiming"> <level value="debug" /> </logger> <!-- (2) --> <logger name="jdbc.sqlonly"> <level value="warn" /> </logger> <!-- (3) --> <logger name="jdbc.audit"> <level value="warn" /> </logger> <!-- (4) --> <logger name="jdbc.connection"> <level value="warn" /> </logger> <!-- (5) --> <logger name="jdbc.resultset"> <level value="warn" /> </logger> <!-- (6) --> <logger name="jdbc.resultsettable"> <level value="debug" /> </logger>
項番 説明 Warning
ロガーによっては大量にログが出力されるので、必要なロガーのみ定義、または出力対象にすること。
上記サンプルでは、開発中の非常に有効なログを出力するロガーについて、ログレベルを
"debug"に設定している。 その他のロガーについては、必要に応じて"debug"に設定する必要がある。性能試験及び商用環境にリリースする場合、正常終了時にlog4jdbc用のロガーによってログが出力されないようにすること。
具体的には、ログレベルを
"warn"に設定する。
5.1.2.3.3. log4jdbcのオプションの設定¶
クラスパス直下に、log4jdbc.propertiesというプロパティファイルを配置することで、log4jdbcのデフォルトの動作をカスタマイズすることができる。
log4jdbc.properties
# (1) log4jdbc.dump.sql.maxlinelength=0 # (2)
項番 説明 SQL分の折り返し文字数を指定する。0を指定すると、折り返しはされない。 オプションの詳細については、log4jdbc project pageを参照されたい。
5.1.3. How to extend¶
5.1.3.1. 複数データソースを使用するための設定¶
Todo
TBD
今後、以下の内容を追加する予定である。
- 複数データソースを使う際の注意点などを踏まえた設定例。
- 実装にも影響がある場合は、実装例。
5.1.4. how to solve the problem¶
5.1.4.1. N+1問題の対策方法¶
N+1問題とは、データベースから取得するレコード数に比例して実行されるSQLの数が増えることにより、データベースへの負荷およびレスポンスタイムの劣化を引き起こす問題のことである。
以下に、具体的をあげる。
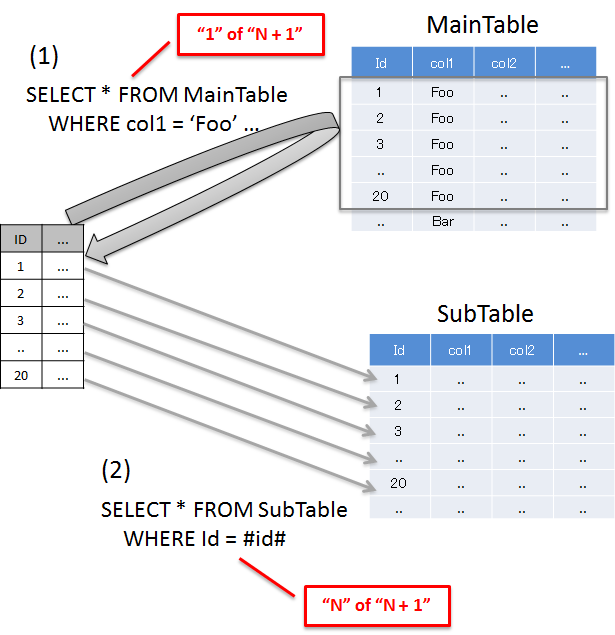
項番 説明 'Foo'のレコードを取得しており、20件のレコードが取得されている。
N+1問題の解決方法の代表例を、以下に示す。
5.1.4.1.1. JOIN(Join Fetch)を使用して解決する¶
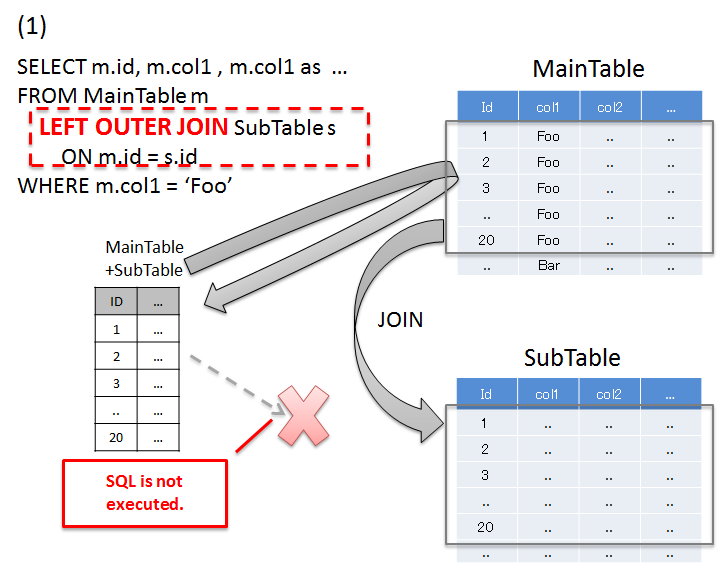
項番 説明 'Foo'のレコードと、検索条件に一致したレコードのidが一致するSubTableのレコードを一括で取得している。カラム名が重複する場合は、別名を付与してどちらのテーブルのカラムなのか識別する必要がある。JOIN(Join Fetch)を使用すると、1回のSQLの発行で必要なデータを全て取得することができる。Warning
関連テーブルとの関連が、1:Nの場合は、JOIN(Join Fetch)による解決も可能だが、以下の点に注意すること。
- 1:Nの関連をもつレコードをJOINする場合、関連テーブルのレコード数に比例して、無駄なデータを取得することになる。 詳細については、一括取得時の注意事項を参照されたい。
- JPA(Hibernate)使用する際に、1:NのNの部分が、複数ある場合は、Nの部分を格納するコレクション型は、
java.util.Listではなく、java.util.Setを使用する必要がある。
5.1.4.1.2. 関連レコードを一括で取得する事で解決する¶
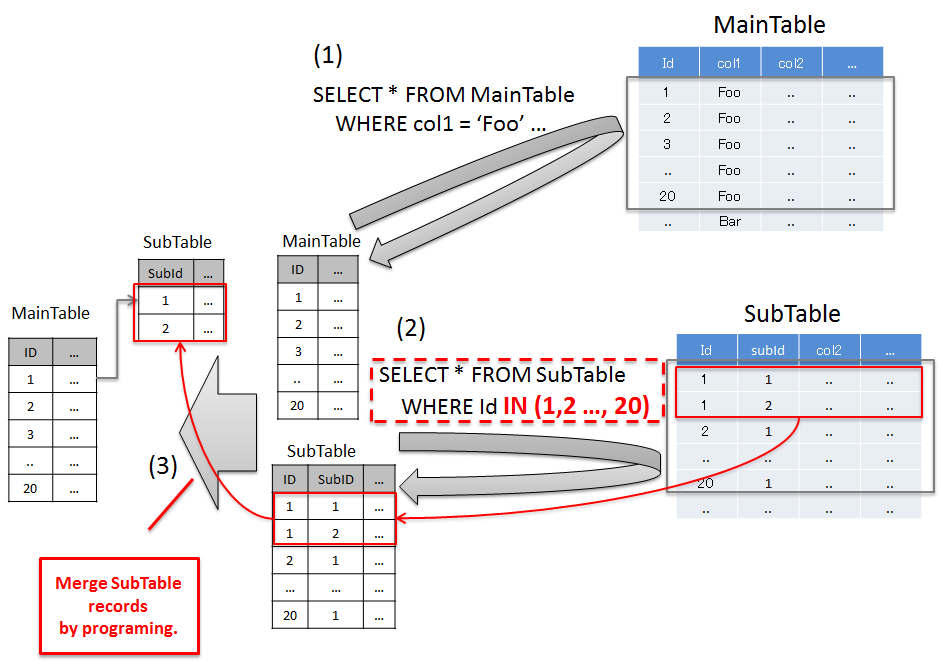
項番 説明 'Foo'のレコードを取得しており、20件のレコードが取得されている。Note
この方法は、SQLの発行を最小限におさえつつ、必要なデータのみ取得することができるという特徴をもつ。 関連テーブルのレコードをプログラミングによって振り分ける必要があるが、関連テーブルの数が多い場合や、1:NのNのレコード数が多い場合は、この方法で解決する方がよいケースがある。
5.1.5. Appendix¶
5.1.5.1. LIKE検索時のエスケープについて¶
LIKE検索を行う場合は、検索条件として使用する値を、LIKE検索用にエスケープする必要がある。
共通ライブラリでは、LIKE検索用のエスケープ処理を行うためのコンポーネントとして、以下のクラスを提供している。
| 項番 | クラス | 説明 |
|---|---|---|
org.terasoluna.gfw.common.query.
QueryEscapeUtils
|
SQL及びJPQLのエスケープ処理を行うメソッドを提供するユーティリティクラス。 本クラスでは、
を提供している。 |
|
org.terasoluna.gfw.common.query.
LikeConditionEscape
|
LIKE検索用のエスケープ処理を行うクラス。 |
Note
LikeConditionEscapeクラスは、「LIKE検索用のワイルドカード文字の扱いに関するバグ」を修正するために、
terasoluna-gfw-common 1.0.2.RELEASEから追加したクラスである。
LikeConditionEscapeクラスは、データベース及びデータベースのバージョンの違いによるワイルドカード文字の違いを吸収する役割を持つ。
5.1.5.1.1. 共通ライブラリのエスケープ仕様について¶
共通ライブラリから提供しているエスケープ処理の仕様は、以下の通りである。
- エスケープ文字は「
"~"」。 - エスケープ対象文字は、デフォルトでは「
"%","_"」の2文字。
Note
エスケープ対象文字は、terasoluna-gfw-common 1.0.1.RELEASEまでは「 "%" , "_" , "%" , "_"」の4文字であったが、
「LIKE検索用のワイルドカード文字の扱いに関するバグ」を修正するために、
terasoluna-gfw-common 1.0.2.RELEASEより「 "%" , "_"」の2文字に変更している。
なお、エスケープ対象文字として全角文字「"%" , "_"」を含めてエスケープする方法も提供している。
具体的なエスケープ例を以下に示す。
[デフォルト仕様のエスケープ例]
エスケープ対象文字としてデフォルト値を使用する場合のエスケープ例を以下に示す。
"a""a"無 エスケープ対象文字が含まれていないため、エスケープされない。
"a~""a~~"有 エスケープ文字が含まれているため、エスケープされる。
"a%""a~%"有 エスケープ対象文字が含まれているため、エスケープされる。
"a_""a~_"有 No.3と同様。
"_a%""~_a~%"有 エスケープ対象文字が含まれているため、エスケープされる。エスケープ対象文字が複数存在する場合はすべてエスケープされる。
"a%""a%"無 No.1と同様。
terasoluna-gfw-common 1.0.2.RELEASEより、デフォルト仕様では「
"%"」はエスケープ対象外の文字として扱う。
"a_""a_"無 No.1と同様。
terasoluna-gfw-common 1.0.2.RELEASEより、デフォルト仕様では「
"_"」はエスケープ対象外の文字として扱う。
" "" "無 No.1と同様。
""""無 No.1と同様。
nullnull無 No.1と同様。
[全角文字を含める場合のエスケープ例]
エスケープ対象文字として全角文字を含める場合のエスケープ例を以下に示す。 項番6と7以外は、デフォルト仕様のエスケープ例を参照されたい。
"a%""a~%"有 エスケープ対象文字が含まれているため、エスケープされる。
"a_""a~_"有 No.6と同様。
5.1.5.1.2. 共通ライブラリから提供しているエスケープ用のメソッドについて¶
共通ライブラリから提供しているQueryEscapeUtilsクラスとLikeConditionEscapeクラスのLIKE検索用のエスケープメソッドの一覧を、以下に示す。
項番 メソッド名 説明
toLikeCondition(String)
toStartingWithCondition(String) "%"を付与する。前方一致検索用の値に変換する場合に使用するメソッドである。
toEndingWithCondition(String) "%"を付与する。後方一致検索用の値に変換する場合に使用するメソッドである。
toContainingCondition(String) "%"を付与する。部分一致検索用の値に変換する場合に使用するメソッドである。Note
No.2, 3, 4 については、SQLやJPQL側で一致方法(前方一致、後方一致、部分一致)を指定するのではなく、プログラム側で指定する時に使用するメソッドである。
5.1.5.1.3. 共通ライブラリの使用方法¶
LIKE検索時のエスケープ処理の実装例については、使用するO/R Mapper向けのドキュメントを参照されたい。
- JPA(Spring Data JPA)を使用する場合は、データベースアクセス(JPA編)のLIKE検索時のエスケープについてを参照されたい。
- Mybatis2(TERASOLUNA DAO)を使用する場合は、データベースアクセス(Mybatis2編)のLIKE検索時のエスケープについてを参照されたい。
Note
エスケープ処理を行うために使用するAPIは、使用するデータベースがサポートしているワイルドカード文字によって使い分ける必要がある。
[ワイルドカードとして「 “%” , “_”」(半角文字)のみをサポートしているデータベースの場合]
String escapedWord = QueryEscapeUtils.toLikeCondition(word);
QueryEscapeUtilsクラスのメソッドを直接使用して、エスケープ処理を行う。
[ワイルドカードとして「”%” , “_”」(全角文字)もサポートしているデータベースの場合]
String escapedWord = QueryEscapeUtils.withFullWidth() // (2) .toLikeCondition(word); // (3)
QueryEscapeUtilsメソッドのwithFullWidth()メソッドを呼び出して、LikeConditionEscapeクラスのインスタンスを取得する。(2)で取得した LikeConditionEscapeクラスのインスタンスのメソッドを使用して、エスケープ処理を行う。
5.1.5.2. Sequencerについて¶
Note
共通ライブラリとしてSequencerを用意した理由
Sequencerを用意した理由は、JPAの機能として提供されているID採番機能において、シーケンス値を文字列としてフォーマットする仕組みがないためである。 実際のアプリケーション開発では、フォーマットされた文字列をプライマリキーに設定するケースもあるため、共通ライブラリとしてSequencerを提供している。
プライマリキーに設定する値が数値の場合は、JPAの機能として提供されているID採番機能を使用することを推奨する。JPAのID採番機能については、データベースアクセス(JPA編)のEntityの追加を参照されたい。
Sequencerを用意した主な目的は、JPAでサポートされていない機能の補完であるが、JPAと関係ない処理で、シーケンス値が必要な場合に、使用することもできる。
5.1.5.2.1. 共通ライブラリから提供しているクラスについて¶
項番 クラス名 説明
SequencerインタフェースのJDBC用の実装クラス。データベースにSQLを発行してシーケンス値を取得するためのクラスである。データベースのシーケンスオブジェクトから値を取得することを想定したクラスではあるが、データベースにストアードされているファンクションを呼び出すことで、シーケンスオブジェクト以外から値を取得することもできる。
5.1.5.2.2. 共通ライブラリの利用方法¶
Sequencerをbean定義する。
xxx-infra.xml
<!-- (1) --> <bean id="articleIdSequencer" class="org.terasoluna.gfw.common.sequencer.JdbcSequencer"> <!-- (2) --> <property name="dataSource" ref="dataSource" /> <!-- (3) --> <property name="sequenceClass" value="java.lang.String" /> <!-- (4) --> <property name="nextValueQuery" value="SELECT TO_CHAR(NEXTVAL('seq_article'),'AFM0000000000')" /> <!-- (5) --> <property name="currentValueQuery" value="SELECT TO_CHAR(CURRVAL('seq_article'),'AFM0000000000')" /> </bean>
項番 説明 org.terasoluna.gfw.common.sequencer.Sequencerインタフェースを実装したクラスを、bean定義する。上記例では、SQLを発行してシーケンス値を取得するためのクラス(JdbcSequencer)を指定している。java.lang.String型を指定している。1の場合、"A0000000001"がSequencer#getNext()メソッドの返り値として返却される。2の場合、"A0000000002"がSequencer#getCurrent()メソッドの返り値として返却される。
bean定義したSequencerからシーケンス値を取得する。
- Service
// omitted // (1) @Inject @Named("articleIdSequencer") // (2) Sequencer<String> articleIdSequencer; // omitted @Transactional public Article createArticle(Article inputArticle) { String articleId = articleIdSequencer.getNext(); // (3) inputArticle.setArticleId(articleId); Article savedArticle = articleRepository.save(inputArticle); return savedArticle; }
項番 説明 SequencerオブジェクトをInjectする。上記例では、シーケンス値は、フォーマットされた文字列として取得するため、Sequencerのジェネリックス型には、java.lang.String型を指定している。@javax.inject.Namedアノテーションのvalue属性に指定する。上記例では、xxx-infra.xmlに定義したbean名("articleIdSequencer")を指定している。Sequencer#getNext()メソッドを呼び出し、次のシーケンス値を取得する。上記例では、取得したシーケンス値を、EntityのIDとして使用している。現在のシーケンス値を取得する場合は、Sequencer#getCurrent()メソッドを呼び出す。Tip
bean定義する
Sequencerが一つの場合は、@Namedアノテーションが省略できる。複数指定する場合は、@Namedアノテーションを使用して、bean名の指定が必要となる。
5.1.5.3. Spring Frameworkから提供されているデータアクセス例外へ変換するクラス¶
Spring Frameworkのデータアクセス例外へ変換する役割を持つクラスを、以下に示す。
Spring Frameworkのデータアクセス例外への変換クラス¶ 項番 クラス名 説明
JPA(Hibernateの実装)を使った場合、本クラスによって、O/R Mapper例外がSpring Frameworkのデータアクセス例外に変換される。
JPA(Hibernateの実装)を使った場合、本クラスによって、JDBC例外とO/R Mapper例外に変換される。
Mybatisや、JdbcTemplateを使った場合、本クラスによって、JDBC例外が、Spring Frameworkのデータアクセス例外に変換される。変換ルールは、XMLファイルに記載されており、デフォルトで使用されるXMLファイルは、spring-jdbc.jar内のorg/springframework/jdbc/support/sql-error-codes.xmlとなる。 クラスパス直下に、XMLファイル(sql-error-codes.xml)を配置することで、デフォルトの動作を変更することもできる。
5.1.5.4. Spring Frameworkから提供されているJDBCデータソースクラス¶
Spring Frameworkから提供されているJDBCデータソース¶ 項番 クラス名 説明
アプリケーションからコネクションの取得依頼があったタイミングで、 java.sql.DriverManager#getConnectionを呼び出し、新しいコネクションを生成するデータソースクラス。 コネクションのプーリングが必要な場合は、アプリケーションサーバのデータソース、または、OSS/Third-Partyライブラリから提供されているデータソースを使用すること。
DriverManagerDataSourceの子クラスで、一つのコネクションを使いまわす実装になっており、シングルスレッドで動くユニットテスト向けのデータソースクラスである。 ユニットテストでも、マルチスレッドでデータソースにアクセスする場合は、本クラスを使用すると、期待した動作にならないことがあるので、注意が必要である。
アプリケーションからコネクションの取得依頼があったタイミングで、 java.sql.Driver#getConnectionを呼び出し、新しいコネクションを生成するデータソースクラス。 コネクションのプーリングが必要な場合は、アプリケーションサーバのデータソース、または、OSS/Third-Partyライブラリから提供されているデータソースを使用すること。
Spring Frameworkから提供されているJDBCデータソースのアダプター¶ 項番 クラス名 説明
トランザクション管理されていないデータソースを、Spring Frameworkのトランザクション管理対象にするためのアダプタークラス。
実行中のトランザクションの独立性レベルによって、使用するデータソースを切り替えるためのアダプタークラス。